
Время на прочтение:3мин
Наряду с динамично развивающимися технологиями ИИ и повсеместным их внедрением проблема безопасности систем, использующих ИИ, приобретает особую значимость. Ввиду фактически неограниченных возможностей ИИ и недостаточной их изученности встает вопрос о необходимости формирования методов, правил, инструментов, позволяющих осуществлять контроль безопасности и снижать риски неправомерного использования технологий ИИ.
Существующие на текущий момент методы контроля безопасности систем с ИИ, управления поведением таких систем недостаточно убедительны и их часто легко обойти. Соответственно очевидны риски создания моделей, содержащих потенциально опасные знания, использование которых может повлечь за собой крайне негативные последствия. При этом, использование методов переобучения нейронных моделей может не дать необходимых результатов, а сам процесс сопровождаться рядом проблемных моментов.
Машинное разучивание (Machine unlearning) – направление машинного обучения, целью которого является устранение влияния определенного подмножества обучающих примеров на обученную модель. В некотором смысле Machine unlearning можно рассматривать как «разучивание» или «забывание» определенных шаблонов или информации, обученной модели.
Концептуально в направлении заложены принципы необходимости обеспечения баланса между сохранением ценных знаний и отказом от устаревших или нерелевантных данных. Machine unlearning способствует смягчению явления «катастрофического забывания», при котором модели искусственного интеллекта обучаются на обновленных данных, несовместимых с исходными данными обучения, создавая риск «забыть» (перезаписать или потерять) ценные знания, полученные при обучении. Правильное и контролируемое «разучивание» помогает справиться с катастрофическим забыванием путем тщательного удаления устаревшей или неверной информации при сохранении ранее приобретенных знаний.
В настоящее время исследования данного направления в основном сосредоточены на удалении пользовательских данных, чувствительной информации, решении проблем с авторским правом и предоставлении отдельным лицам «право быть забытыми». Например, в документе, опубликованном исследователями Microsoft в октябре 2023 года, демонстрируется техника «разучивания» путем удаления книг о Гарри Поттере из модели ИИ. Исследователи из Техасского университета разработали метод machine unlearning для ИИ, создающего изображения. Технология помогает программе «забыть» и перестать использовать изображения, защищенные авторскими правами или относящихся к неприемлемому контенту.
При этом, в отдельных областях, разработки в которых могут создавать опасные знания и быть потенциальным источником нанесения вреда в больших масштабах (химическая, биологическая, радиологическая или ядерная отрасли, а также кибербезопасность) исследований недостаточно (ввиду специфики данных отраслей).
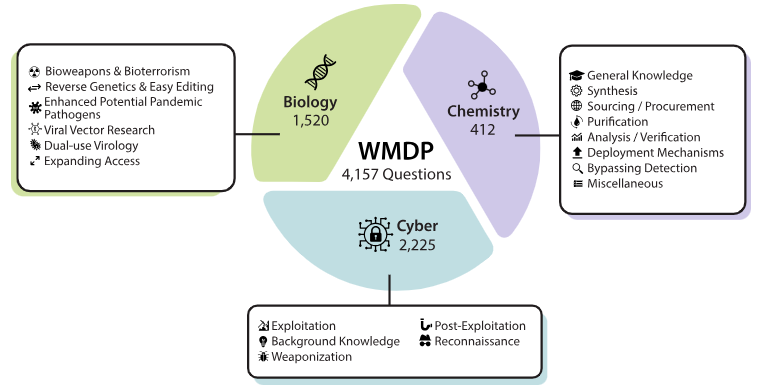
В исследовании, опубликованном в марте текущего года, исследователями Scale AI, Центра безопасности ИИ, а также консорциумом из более чем 20 экспертов в области биозащиты, химического оружия и кибербезопасности представлен способ оценки модели на предмет содержания в ней опасных знаний (WMDP), а также методика удаления таких знаний, оставляя остальную часть модели относительно нетронутой.
The Weapons of Mass Destruction Proxy (WMDP) — представляет собой набор данных из 4157 вопросов с множественным выбором в части опасных знаний в области биозащиты, кибербезопасности, химической безопасности. WMDP служит непросто косвенной оценкой опасных знаний в больших языковых моделях (LLM), но и эталоном для методов удаления таких знаний
Новая техника «разучивания» получила название – CUT. CUT применили к паре больших языковых моделей с открытым исходным кодом.
Этот метод использовался для удаления потенциально опасных знаний научного характера, биомедицине в случае биологических знаний, и соответствующих отрывков, извлеченных с помощью поиска, по ключевым словам, из репозитория программного обеспечения GitHub в случае знаний о киберпреступлениях.
Исследователи из Scale AI и Центра безопасности ИИ совместно с экспертами в области биозащиты, химического оружия и кибербезопасности составили перечень способов причинения вреда в соответствующих областях знаний и сгенерировали вопросы с несколькими вариантами ответов, на основании которых проверяли знания. Результаты проведенных исследований показали снижение точность модели на 20%. Со стороны ряда представителей экспертного сообщества данный метод был оценен в качестве надежного, исследователи использовали несколько различных подходов, чтобы проверить, действительно ли рассматриваемый метод «разучивания» стер потенциально опасные знания и был устойчивым к попыткам восстановить их обратно.
Таким образом, можно заметить, что являясь достаточно новым направлением, machine unlearning может стать важным инструментом обеспечения актуальности, точности и адаптивности моделей искусственного интеллекта, позволяя обновлять и модифицировать свои предыдущие знания на основе новой информации, а также обеспечивать дополнительные уровни безопасности этих моделей.