
Порой разработчики во время работы придумывают безумные идеи проектов, и они даже пытаются их реализовывать. Подобное ощутил и фулстек-разработчик Дмитрий Пацура, когда решил написать компилятор для TypeScript на… TypeScript, используя LLVM.
А что из этого вышло, Дмитрий изложил на прошедшей HolyJS 2019 Moscow. Под катом вы найдете видео и конспект его доклада.
Сначала Дмитрий постарался ответить на вопрос, почему JavaScript использует виртуальную машину, состоящую из интерпретатора и оптимизирующего JIT-компилятора, вместо AoT-компилятора. В этом контексте спикер затронул трансляторы, байт-код, а также устройство виртуальной машины и JIT-компилятора.
Затем Дмитрий перешел к главному вопросу: почему не существует компилятора для TypeScript и что нужно для его реализации. Для этого спикер затронул такие темы, как LLVM, TypeScript в качестве фреймворка, системы типов, устройство объектов внутри V8 и массивы.
→ Код вы можете найти на GitHub
Структура поста
- Транслятор vs. интерпретатор vs. компилятор vs. оптимизирующий JIT-компилятор
- Мистический байт-код
- Виртуальные машины
- Компилятор
- Финальная архитектура
Транслятор vs. интерпретатор vs. компилятор vs. оптимизирующий JIT-компилятор
Транслятор — это программа, которая преобразовывает код из одного языка в другой. Он бывает трех типов: интерпретатор, компилятор и JIT-компилятор.
Интерпретатор
Интерпретатор — программа, которая берет какой-то исходный файл и выполняет его. Можно говорить, что перед интерпретатором есть компилятор, который компилирует, к примеру, JavaScript в байт-код, который уже обрабатывается интерпретатором байт-кода, и это будет правильно. Но никто так не говорит, ибо такой подход уже стал неким стандартом в написании.
Главная задача интерпретатора — быть быстрым. Чем меньше накладных расходов он вносит, тем быстрее он работает, что способствует уменьшению времени исполнения программы. У интерпретатора есть минусы:
- Малое количество оптимизаций. На каждую оптимизацию интерпретатор тратит время, и некоторые из них нужны только для синтетики.
- Проблема «горячего кода». Интерпретатор представляет собой некую абстракцию, которая выполняет код, проходя по байт-коду. Это не напрямую машинный код программы, а абстракция, которая стоит времени для исполнения программы.
- Программа медленнее, чем нативная программа.
- Программу невозможно запустить без интерпретатора.
Компилятор
Компилятор для TypeScript преобразует TypeScript в JS-код, а компилятор для C++ преобразует С++ в машинный код.
Главная задача компилятора — это эффективная трансляция. Время компиляции не так важно. Главное, чтобы компилятор сгенерировал очень качественный код, который будет работать быстро, и сделал наибольшее количество проверок в ahead-of-time. Отсюда вытекают минусы компиляторов:
- Не хватает JIT-оптимизации, потому что компилятор всё делает в ahead-of-time. Но к примеру, в GCC есть profile guide optimization, благодаря которой вы можете скомпилировать программу с неким анализатором, тот в рантайме соберет отчет, и на его основании можете перекомпилировать программу еще раз и получить рост производительности.
- Проблема с потреблением памяти и временем работы.
JIT-компилятор
Есть отдельная категория компиляторов, которые работают в рантайме — just in time компиляторы или просто JIT-компиляторы. Они компилируют код не в какой-то бинарный файл, а прямо в страницы памяти. Из-за этого возникает несколько проблем:
- Безопасность. В W^X есть возможность процессора запускать странички памяти и напрямую исполнять их код.
- Невозможность запуска программы без компиляции её в рантайме. Поэтому время выполнения вашей программы состоит из времени компиляции и времени исполнения.
- Большое потребление оперативной памяти.
Мистический байт-код
Байт-код — это некий intermediate representation или прослойка, которая более низкоуровневая, чем JavaScript, но более высокоуровневый, чем Assembler. В его основу легли несколько принципов: простота, портативность, эффективное хранение, а как результат мы получили дополнительные возможности для SSA-нотаций и CFG (Control Flow Graph).

Выше показан пример байт-кода в V8 для сложения чисел 4 и 3. В левой части — байт-код в hex-виде, а в правой — человекочитаемая форма. Рассмотрим, из чего он состоит.
Первая колонка — это Operation Code Number или ID операции. Он записан в одном байте, значит, он принимает только числа от 0 до 255 или от 00 до FF в hex-виде. По ID понятно, что 0c — это инструкция LdaSmi, а 26 — инструкция Star.
Вторая колонка — это операнд или аргумент функции. Понятно, 04 — это [4], а fb — это регистр r0.
Всё это сильно поменялось, когда появился байт-код. Его начали везде пихать — в интерпретаторы, компиляторы, без разницы. Это просто слой, из которого удобно писать что в виртуальную машину, что в компиляторы.
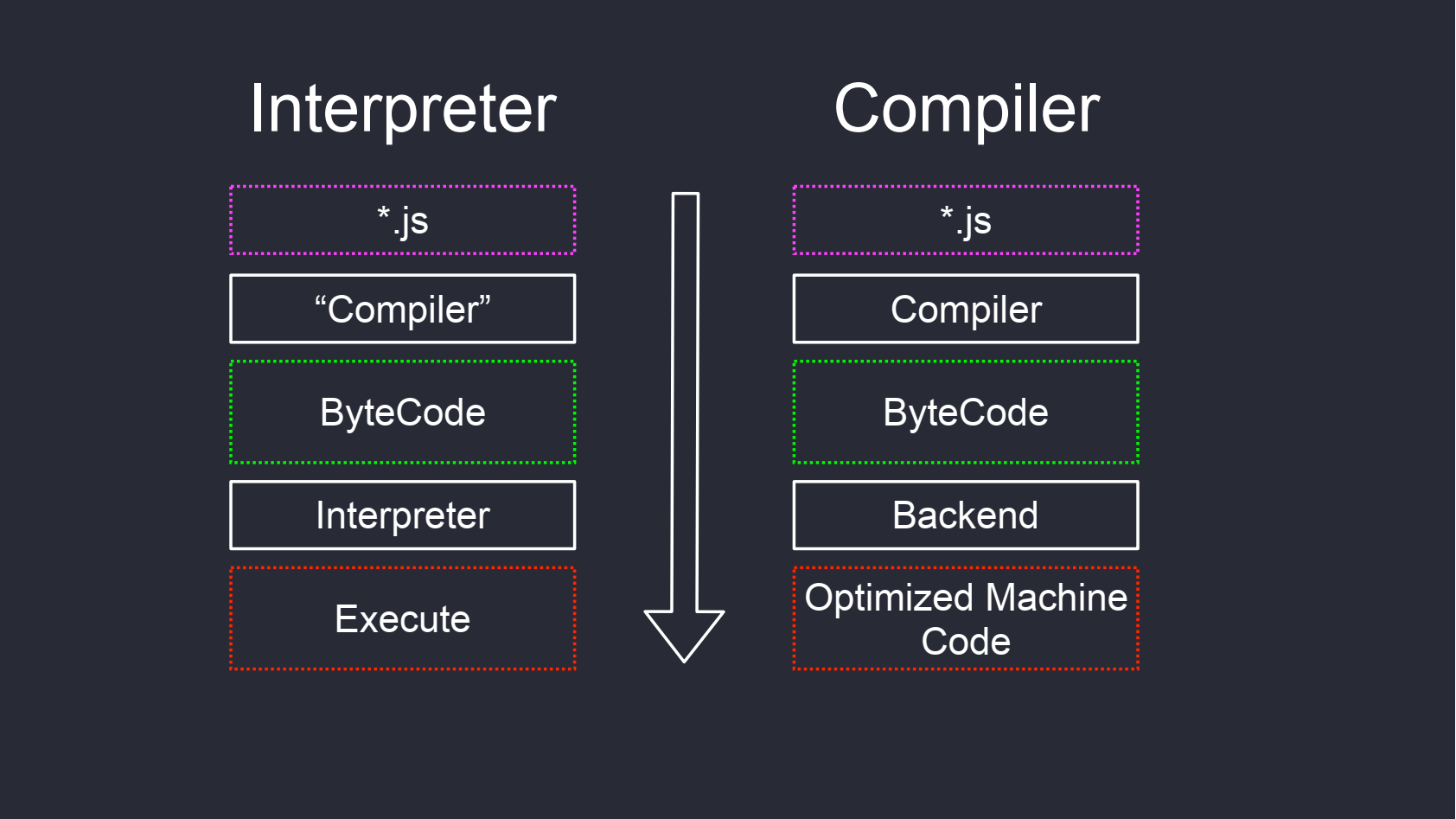
Но байт-код можно использовать абсолютно по-разному.
PHP
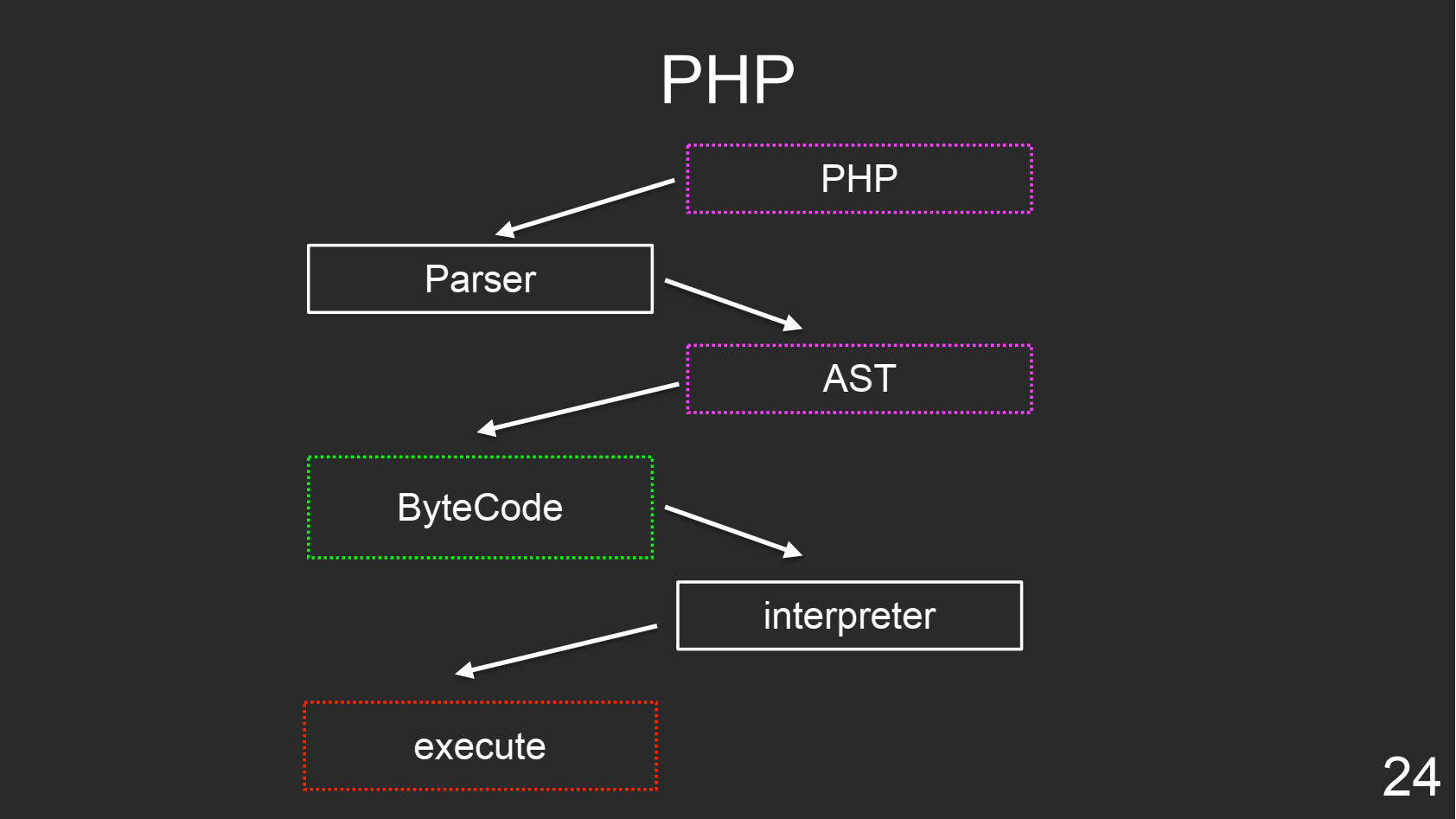
PHP — интерпретируемый язык, который запускается каждый раз, в этом его и проблема — он не демонизированный. Но для него есть расширение opcache, которое позволяет кэшировать байт-код, чтобы не парсить файл каждый раз. Это дает прирост в производительности. Кроме того, можно один раз оптимизировать байт-код, закешировать и больше никогда не оптимизировать.
Java
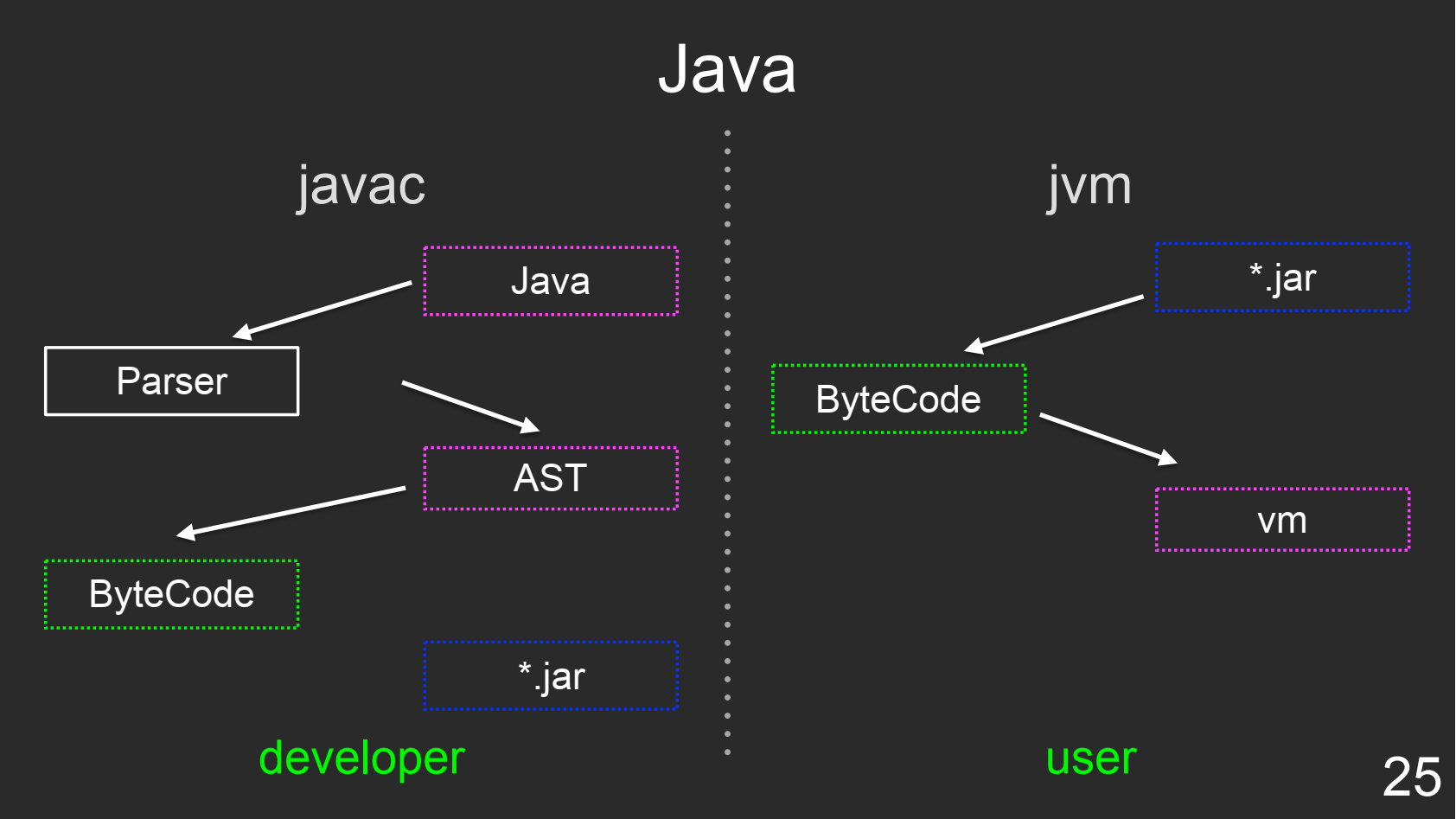
Разработчик пишет программу на Java и отдает javac. javac все это парсит, условно собирает байткод и пакует его в jar-архив. Далее полученный jar-файл отдаем конечному пользователю. Ему не нужно ничего компилировать: конечный архив с байткодом после распаковки летит напрямую в виртуальную машину JVM.
Facebook Hermes
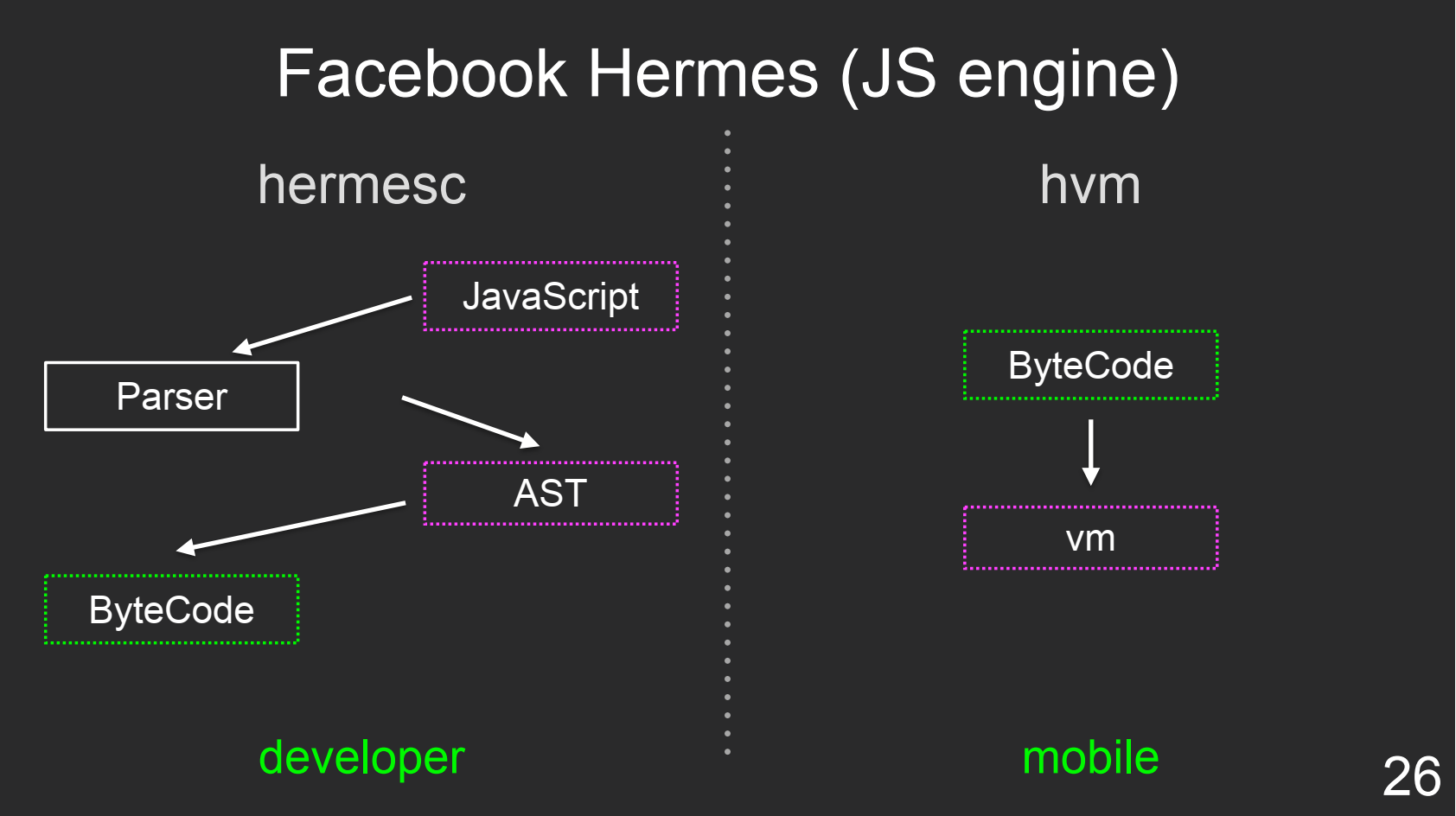
Facebook Hermes — это виртуальный движок для JavaScript от команды Facebook. Хоть под React Native мы пишем на JS, ребята использовали Java-подход: hermesc (hermes compiler) для разработчика и HVM (hermes virtual machine) для конечного пользователя.
V8
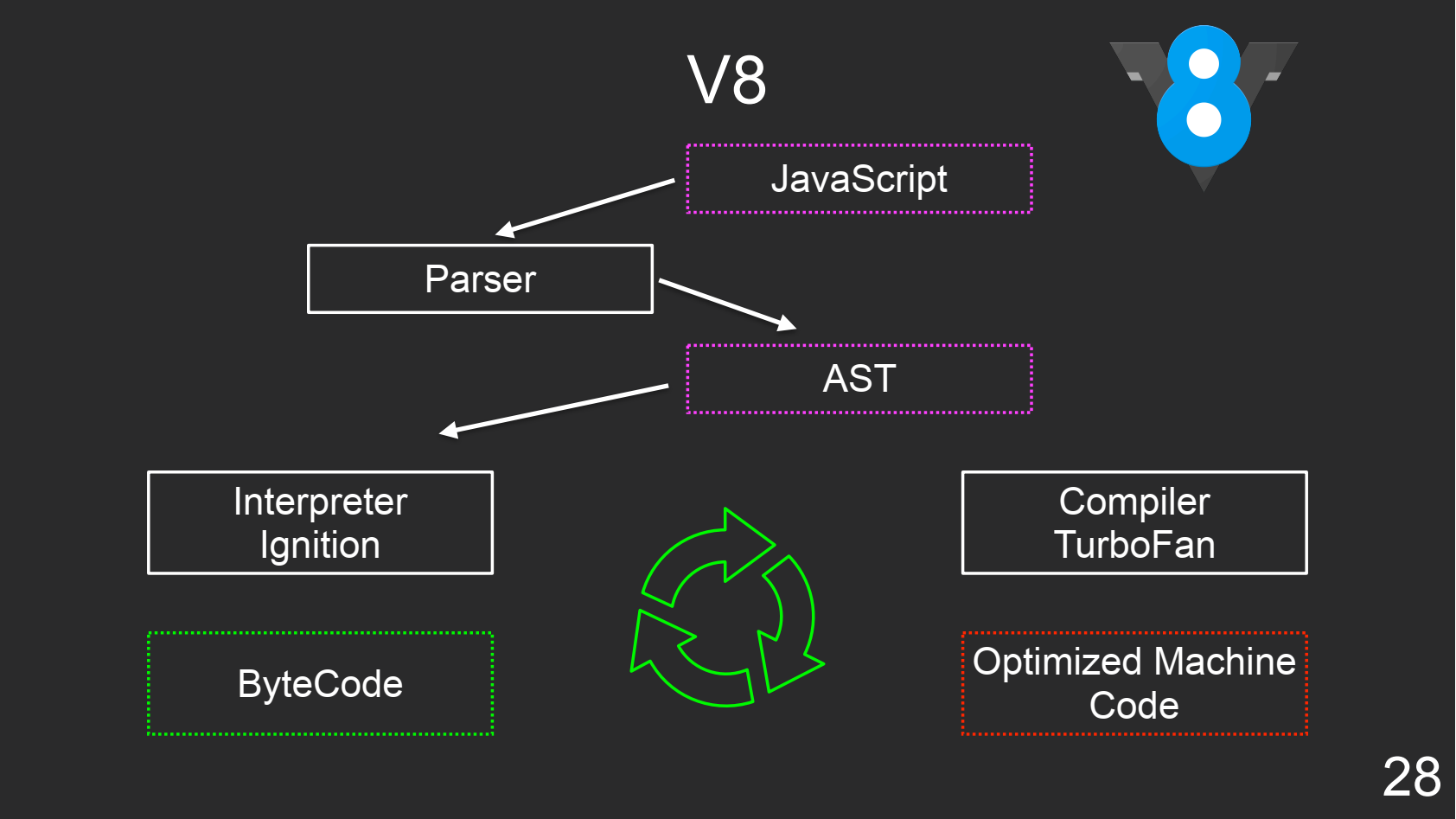
В V8 есть интерпретатор и оптимизирующий JIT-компилятор, который используется для устранения проблем «горячего» кода.
Node.js
А можно ли реализовать Java-подход в NodeJS?

Можно с помощью проекта ByteNode. Он представляет собой обертку CLI над стандартным модулем VM внутри Node.js, который позволяет исполнить любой скрипт, закешировать V8 operation code в бинарном представлении и положить так, как V8 хранит байт-код.
Этот байт-код мы можем упаковать, к примеру, в бэкенде в Docker-образ и отправить в продакшн. Это неплохая обфускация, потому что для V8 не существует детрансляторов (из байт-кода обратно в javascript), как для Java, когда байт-код можно декомпилировать обратно в Java-код.
Виртуальные машины
Архитектура процессных виртуальных машин построена таким образом, чтобы запускать софт внутри «песочницы» на железе, которое для него не предназначено. Одной из такой виртуальных машин и является V8.
Типы процессных виртуальных машин
Процессные виртуальные машины бывают двух типов: register based и stack based.
Register based виртуальная машина оперирует регистрами процессора. Поэтому такой тип машин приближен к железу. Примером register based VM служит Dalvik.
Рассмотрим предыдущий пример сложения чисел 3 и 4 на примере register based программы:
0x00001 SET r0, 3 0x00002 SET r1, 4 0x00003 ADD r1, r0
Кладем 3 первой инструкцией в регистр r0, второй инструкцией кладем 4 в регистр r1, а затем с помощью инструкции ADD складываем регистр r0, r1, а полученный результат 7 закидываем в r0. Главное здесь — это типизация.
В отличие от register based VM, stack based виртуальные машины работают с регистрами через абстракцию accumulator, которая представляет собой стек. Напишем программу сложения чисел 3 и 4 в такой VM:
0x00001 LOAD 3 0x00002 PUSH r0 0x00003 LOAD 4 0x00004 ADD r0
Мы не можем загрузить в регистр значение, поэтому сначала загружаем 3 в аккумулятор. Теперь с помощью инструкции PUSH перекидываем 3 из аккумулятора в регистр r0.
Чтобы сложить два числа внутри stack-based виртуальной машины, нужно одно число иметь в регистре, а второе в аккумуляторе. Поэтому 4 закинем в аккумулятор и с помощью инструкции ADD вытаскиваем значение из стека и из регистра, складываем оба и получаем 7.
Теперь сравним оба подхода. Register based VM быстрее stack based VM ввиду отсутствия промежуточного слоя — аккумулятора, но из-за того, что register based виртуальная машина ближе к железу, ее сложнее реализовать. Поэтому напишем интерпретатор на stack based архитектуре.
V8 Interpreter ByteCode.
Ещё раз вернемся к байт-коду V8. Для этого напишем такую программу, где будем складывать числа 3 и 4.
function test() { const a = 4; const b = 3; return a + b; } test();
Дальше запускаем ноду с флагом --print-bytecode:
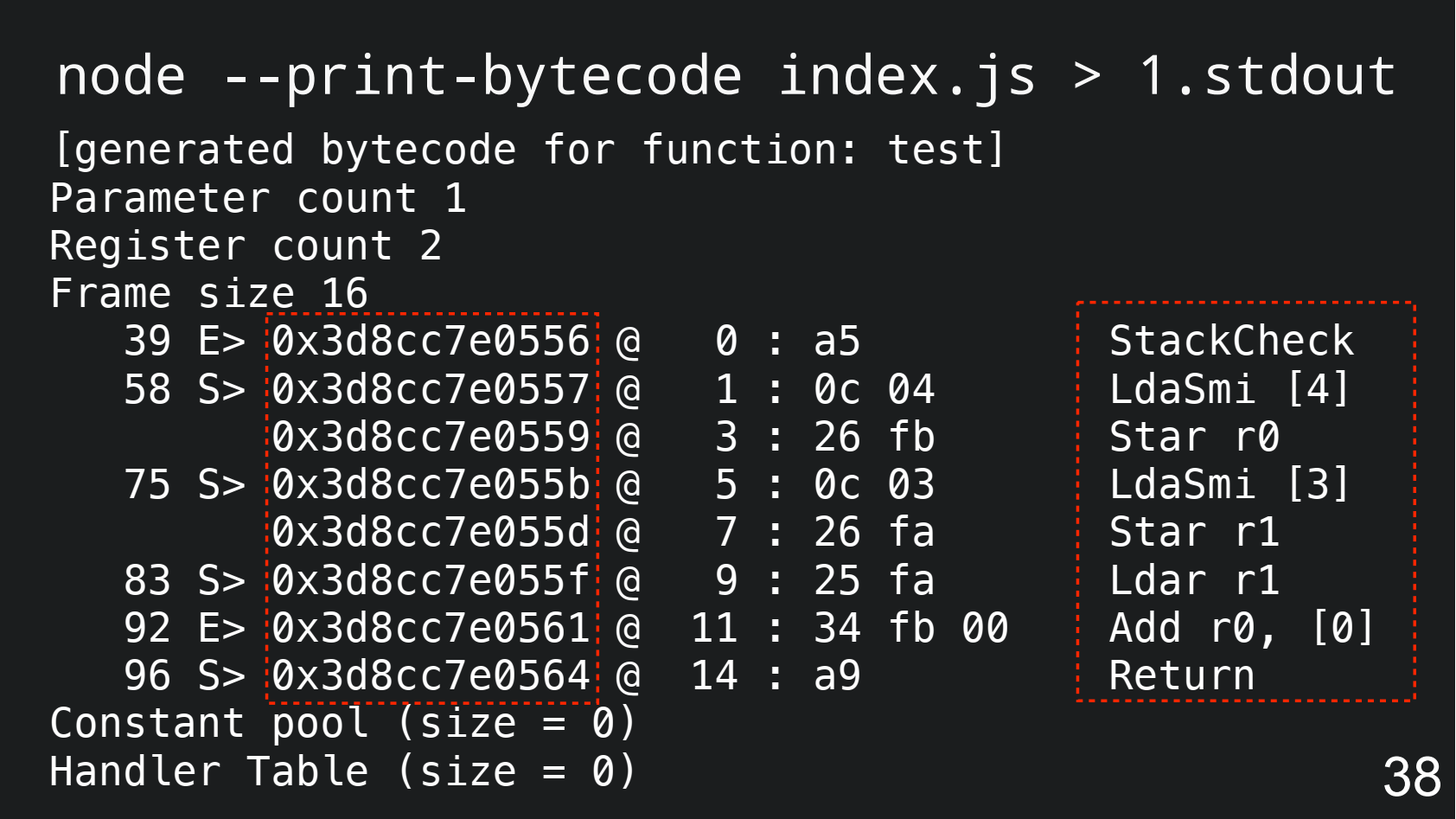
Сама программа для сложения чисел 4 и 3 осталась, но появилась какая-то магия — адреса. Так как байт-код интерпретируется непоследовательно, то он может сделать indirection behavior, когда вы совершаете прыжок (jump). Это нужно для имплементации условий, циклов и т.д.
Итак, stack based интерпретатор написать несложно. Рассмотрим инструкцию LdaZero для загрузки «0» в аккумулятор:
// LdaZero // // Load literal '0' into the accumulator. IGNITION_HANDLER(LdaZero, InterpreterAssembler) { TNode
Программа интерпретируется и доходит до определенного программного кода, для обработки которого виртуальная машина идет искать handler. Машина находит эту функцию, завернутую в макрос IGNITION_HANDLER.
Чтобы закинуть “0” в аккумулятор, нужно зарезервировать константу “0” (Number) и закинуть её в аккумулятор. Затем с помощью функции Dispatch переносим константу к следующему коду.
Инструкция LdaSmi делает то же самое, только для small integer.
V8 ByteCode interpreter on JS
Чтобы лучше во всем разобраться, напишем на JavaScript класс виртуальной машины. В качестве аккумулятора используем обычный массив, а в качестве регистров — объект, поля которого будут именами регистров, например r1, r2. Значения полей же будут значениями этих регистров.
type Accumulator = any[]; type Registers = {[key: string]: any}; class VirtualMachine { protected acc: Accumulator = []; protected registers: Registers = {}; }
По ссылке можно посмотреть, как написать подобный интерпретатор для 10 самых популярных байт-кодов. Нужно всего 100 строчек и никакой магии.
В stack based виртуальной машине нужно одно число держать в аккумуляторе, а другое в регистре, но V8 делает иначе. Он оба числа сначала загружает в аккумуляторы с помощью функции LdaSmi, а затем с помощью Star загружает их в регистры:
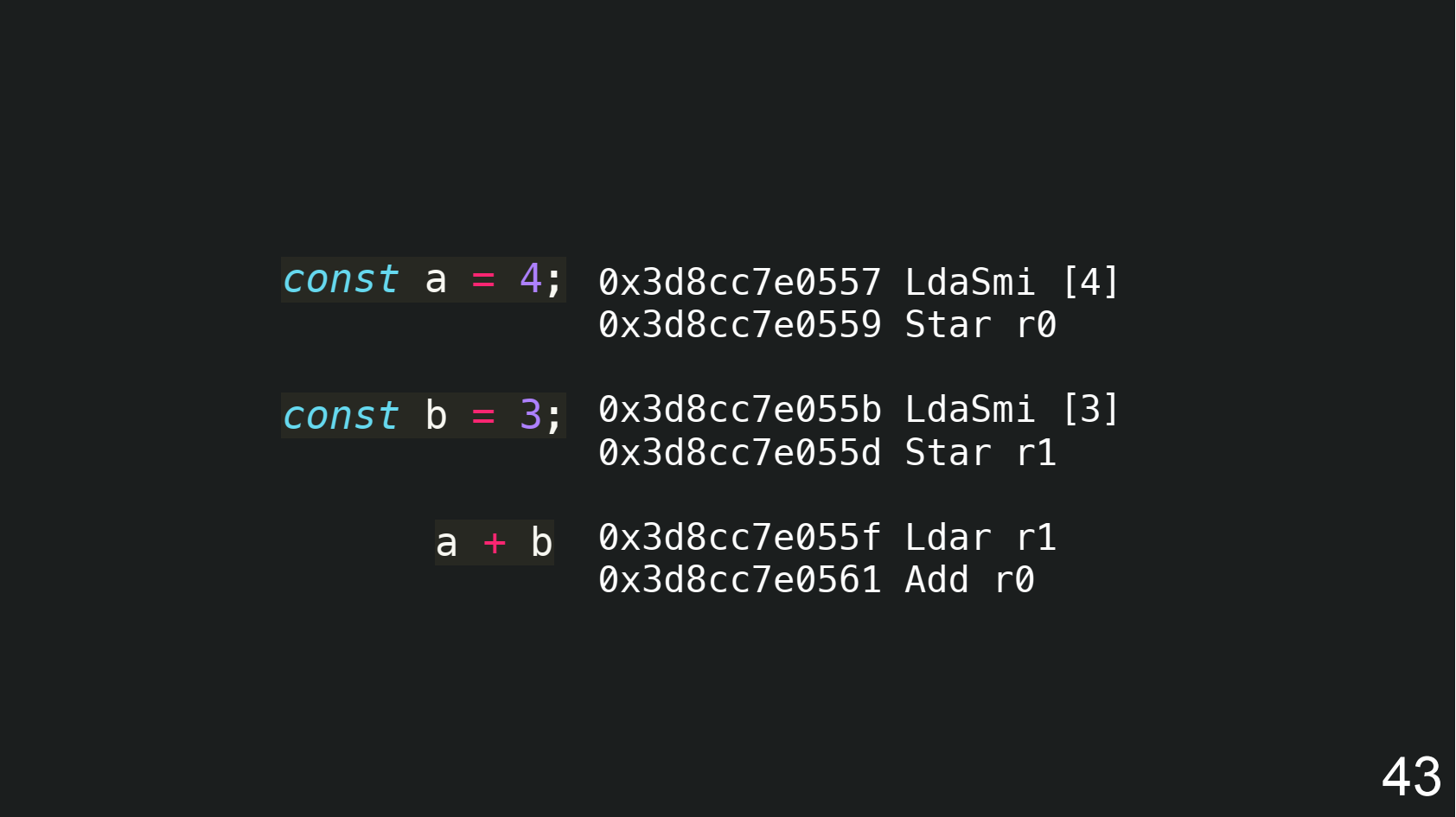
Чтобы сложить числа, нужно одно держать в аккумуляторе. Поэтому в конце V8 выполняет функцию Ldar, которая загружает значение из регистра обратно в аккумулятор. Поэтому один шаг становится лишним.
Как выглядит загрузка 4 из аккумулятора в регистр на JavaScript:
// Load an integer literal into the accumulator LdaSmi: (op) => { this.acc.push(op.operand[0]); }, // Store accumulator to register
Когда мы закинули четверку и тройку в оба регистра, мы пишем инструкцию, которая будет выполнять операцию Ldar. Она запушит значение в аккумулятор, достав его из регистра. И теперь для сложения чисел мы pop-аем аккумулятор, берем значение из регистра, складываем это всё и пушим обратно в аккумулятор, где у нас будет результат:
// Load accumulator with value from register
Я написал небольшую демку на JS. Зеленым она помечает тот код программы, который только что выполнили, а желтым — предыдущий выполненный код, чтобы понимать, когда произойдет прыжок (jump).
Вторая часть демки демонстрирует работу Jump в цикле от 0 до 100. Счетчик a изначально равен нулю. Затем берем цикл, инкрементируем счетчик a, пока a меньше 100, а когда счетчик будет равен 100, то программа выпрыгнет из цикла.
Jit Compiler Machine Code
У V8 есть быстрый интерпретатор Ignition и отдельный JIT-компилятор TurboFan. Ignition в процессе выполнения собирает некоторые метрики. И когда интерпретатор понимает, что какой-то участок кода является «горячим», например через 1000 итераций, он «просит» TurboFan сгенерировать машинный код, чтобы пытаться его исполнять.
Чтобы увидеть машинный код, исполняем команду:d8 --code-comments --print-opt-code jit.js
D8 — это скомпилированный v8 со всеми проверками. Аргумент print-opt-code дает команду печати машинного кода, а code-comments нужен для вывода описания кода на человеческом языке, чтобы понять принципы работы.
Чтобы JIT-ануть код, я решил использовать функцию, которая складывает поля объекта, причем сам объект является аргументом этой функции:
function plus(obj) { return obj.x + obj.y; } console.log(plus({ x: 5, y: 5 })); console.log(plus({ x: 5, y: 5 })); console.log(plus({ x: 5, y: 5 }));
В общем, он не JIT-анул. Почему? Введем буквенное обозначение:
- А — это время выполнения программы из байт-кода. Оно мало из-за быстрого интерпретатора.
- В — время компиляции функции с помощью JIT-компиляторов.
- С — время исполнения функции, скомпилированной JIT-компилятором.
Теперь нужно сравнить время А и В+С. Но Ignition нет смысла компилировать эту функцию, если она исполнена всего три раза. Я решил играть по-крупному и добавлял 0, пока он не начнет JIT-овать:
function plus(obj) { return obj.x + obj.y; } let total = 0; while (total < 100000000) { total += plus({ x: 5, y: 5 }); } console.log(total);
Снова используем трюк: результаты функции кладем в total, потому что JIT-компилятор имеет кучу оптимизаций.
Снова запускаем. Компилятор нашел эту функцию, и TurboFan ее оптимизирует. Далее в консоль выводится 364 инструкции кода. Разберем на схеме, для чего этот JIT-код нужен:

Интерпретатор гоняет байт-код. В какой-то момент Ignition понимает по достаточному количеству метрик, что код «горячий». Поэтому компилятор генерирует функцию, работающую только до четырех (ограничение внутри V8, для уменьшения потребления памяти) типов (механизм шейпов внутри V8).
Сгенерированный код, работает с аргументом, у которого есть шейп с полями x и y. Если кинули туда x и y, то код проходит по быстрому пути, возвращает график потока выполнения внутрь Ignition из скомпилированной функции, а та выполняет сложение результата выполнения функции в переменную total.
Если аргументом функции станет не предназначенный для нее тип (не первые 4 шейпа, для которых сгенерировалась функция), то при вызове функции он выйдет с bailout. Bailout — это механизм выхода из скомпилированной функции, которая не подходит из-за ее ограничений (аргумент не подходящего типа).
Теперь ответим на вопрос: почему JS использует VM (интерпретатор + компилятор), а не AoT-компиляторы. Все из-за области использования, или как мы говорим usage area. JS используется, в основном, в браузерах, а в бэкенд он пришел условно совсем недавно.
А что, если написать компилятор на TypeScript? Его преимущества над JS:
- система типов, которая может нас ограничить;
- можно добавить дополнительные типы вроде unit8;
- можно поддерживать не все функции JS, так как мы пишем свой компилятор.
Компилятор
Как правило, компилятор состоит из двух частей. Первая занимается парсингом, берет AST и делает всевозможные проверки либо оптимизации на уровне AST.
Вторая часть отвечает за кодогенерацию. К примеру, у TypeScript вторая часть генерирует JS-код. Первую часть принято называть фронтендом, вторую — бэкендом. Знакомо? :)
Фронтенд
Напишем на несуществующем языке простую программу, которая выводит в консоль строку «Привет, HolyJS!»:
{ console_log(“Hello HolyJS!”); }
Причем TypeScript выступит в качестве фронтенда. Задействуем его как библиотеку, а не компилятор:
import * as ts from 'typescript'; const options = { lib: [], types: [] }; const files = ['sandbox/hello.ts']; const host = ts.createCompilerHost(options); const program = ts.createProgram(files, options, host);
Импортируем TypeScript и отмечаем в опции, что не существует никаких библиотек и типов, и TS перестал быть JS. Семантически TypeScript остался TypeScript-ом, но у него нет информации о типах что делает его другим языком.
Первая часть нам выдала просто AST-код. Но TypeScript умеет делать проверки на типизацию и всё остальное. Почему бы это не использовать, если он используется как фронтенд? Оказалось, что существует этап перед конечной компиляцией в JS-код который называется PreEmit. Собираем все результаты проверок и распечатываем их:
const diagnostics = ts.getPreEmitDiagnostics(program); if (diagnostics.length) { ts.sys.write( ts.formatDiagnosticsWithColorAndContext( diagnostics, DiagnosticHostInstance ) ); ts.sys.exit( ts.ExitStatus.DiagnosticsPresent_OutputsSkipped ); }
TypeScript вывел, что не может найти такие глобальные типы, как Array, Boolean, Function и т.д., которые он использует как интерфейсы. Дело в том, что парсер TypeScript работает не только с семантикой и лексикой языка, но и с типизацией.
Поэтому создадим файл staticscript.d.ts, чтобы сделать свой язык программирования с семантикой TypeScript:
interface Boolean {} interface Function {} interface IArguments {} interface Number {} interface Object {} interface RegExp {} interface String {} interface Array
Бэкенд
В качестве бэкенда я взял LLVM (Low Level Virtual Machine), внутри которого виртуальная машина, JIT-компилятор, свой язык программирования и куча утилит.
Когда-то в Apple написали Clang в качестве фронтенда для компилятора GCC, но потом решили написать свой бэкенд для Clang. Так и родился проект LLVM.
В LLVM есть свой язык программирования, который называется LLVM IR. Он более высокоуровневый, чем Assembler, а итоговый результат можно сгенерировать на любую целевую архитектуру.
Рассмотрим снова программу сложения 3 и 4, написанной на Си:
#include
Большую часть времени разработки компилятора я брал эталонный фронтенд для LLVM — Clang, выключал все оптимизации и компилировал в LLVM-код с помощью команды:
clang -S -emit-llvm main.cpp -O0
Отключаем оптимизации, чтобы фронтенд внутри Clang не сложил числа 3 и 4 ещё до генерации бэкендом машинного кода.
Так выглядит llvm-код для программы, складывающей два числа.
; ModuleID = ‘main.cpp' source_filename = "main.cpp" target datalayout = "e-m:o-i64:64-f80:128-n8:16:32:64-S128" target triple = “x86_64-apple-macosx10.14.0" define i32 @main() #0 { %1 = alloca i32, align 4 %2 = alloca i32, align 4 %3 = alloca i32, align 4 store i32 3, i32* %1, align 4 store i32 4, i32* %2, align 4 %4 = load i32, i32* %1, align 4 %5 = load i32, i32* %2, align 4 %6 = add nsw i32 %4, %5 store i32 %6, i32* %3, align 4 ret i32 0 }
В source_filename видим имя исходного файла. В datalayout содержится информация об используемых типах, потому что внутри LLVM типы могут собираться на лишние архитектуры. В triple написано, что код сгенерирован в macOS.
Затем идет сама программа. %1 — это переменная с SSA нотацией. Можно, конечно, писать a,b,c, только название переменной можно использовать лишь один раз. Как правило, когда пишут «человеческий» код, пишут a0=0, a1=a0+1, и каждая мутация переменной будет составлять новый индекс. Причем в LLVM отсутствуют такие понятия регистров, только понятия кучи (HEAP) и стека.
Так создаем три указателя и в два из них закидываем числа 3 и 4. Для сложения чисел загружаем их из кучи в стек и складываем, но бэкенд может сгенерировать, например, операцию с регистрами.
В LLVM отсутствуют типы, которыми можно мыслить, например, класс. Там есть простые типы, например, целочисленные: integer, floating, pointer, причем integer можно сделать любой разрядности. Также можно ставить флаги как целочисленные, так и с плавающей точкой. А есть агрегатные типы: векторы, массивы, или структуры.
Очень крутой комментарий, объясняющий, почему стоит использовать LLVM:
Каждый уважающий себя программист хочет сделать свой собственный компилятор. Мечты сбываются! LLVM — важный шаг, позволяющий избежать велосипедостроения.gridem
Чтобы с этим работать, я использую модуль, оборачивающий стандартную вещь внутри LLVM, которая позволяет генерировать intermediate representation код, именуемый IRBuilder.
import * as llvm from 'llvm-node'; const llvmContext = new llvm.LLVMContext(); const llvmModule = new llvm.Module("test", this.llvmContext); const mainFnType = llvm.FunctionType.get( llvm.Type.getVoidTy(llvmContext), false ); const mainFn = llvm.Function.create( mainFnType, LinkageTypes.ExternalLinkage, "main", llvmModule ); const block = llvm.BasicBlock.create(llvmContext, "entry", mainFn); const builder = new llvm.IRBuilder(block);
Чтобы начать генерировать программу, нужно создать контекст и модуль. Внутри модуля сгенерируем отдельную функцию, у которой есть возвращаемый тип. Чтобы сгенерировать код, создаем базовый блок и переводим в него IRBuilder.
Наш бэкенд будет выглядеть следующим образом:
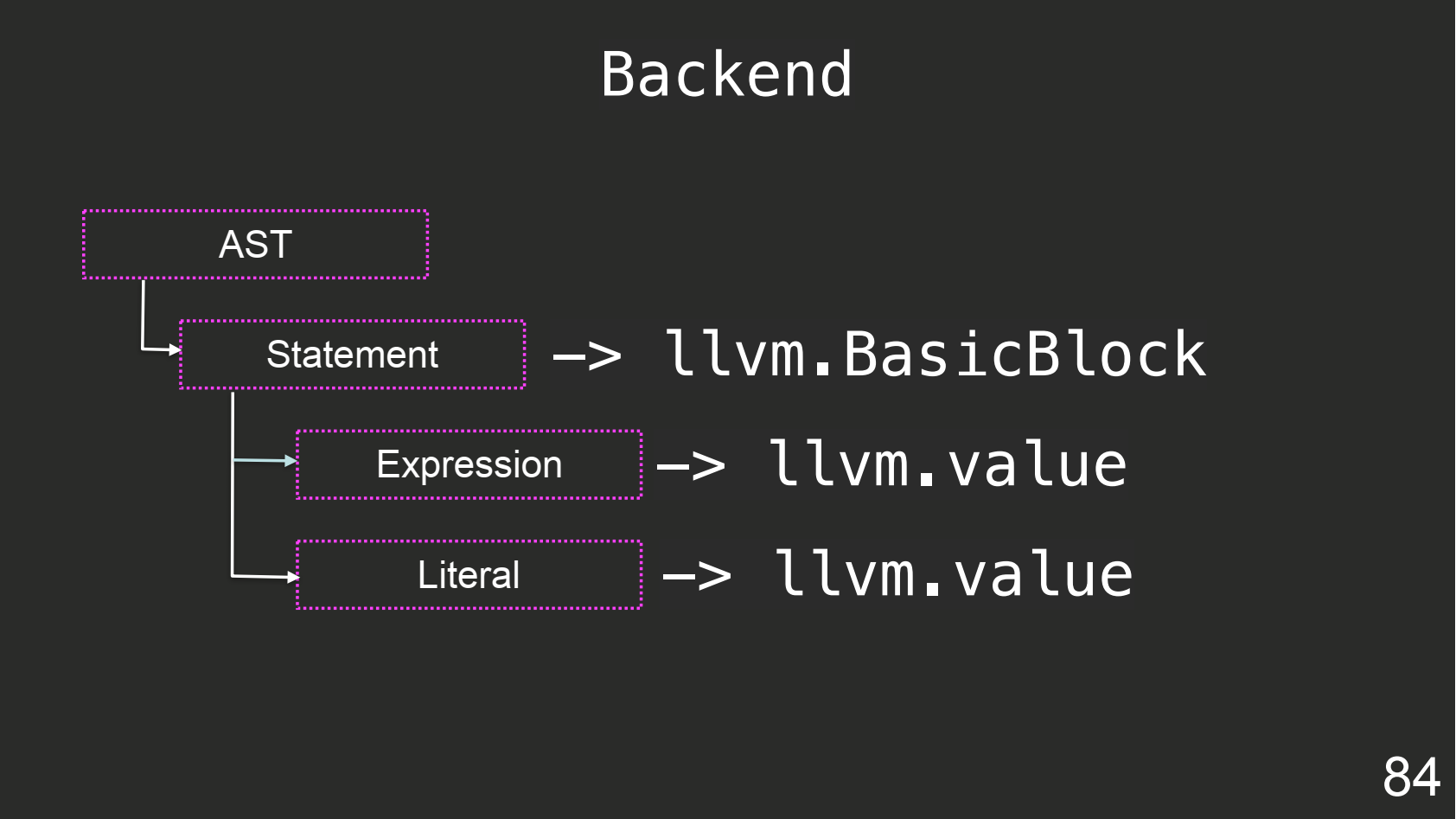
Для того, чтобы это генерировать, нужен IRBuilder и Context. Объект Context хранит контекст LLVM и модулей, ts.TypeChecker для вывода типов из AST-дерева TypeScript и scope, в который кладем map-ы:
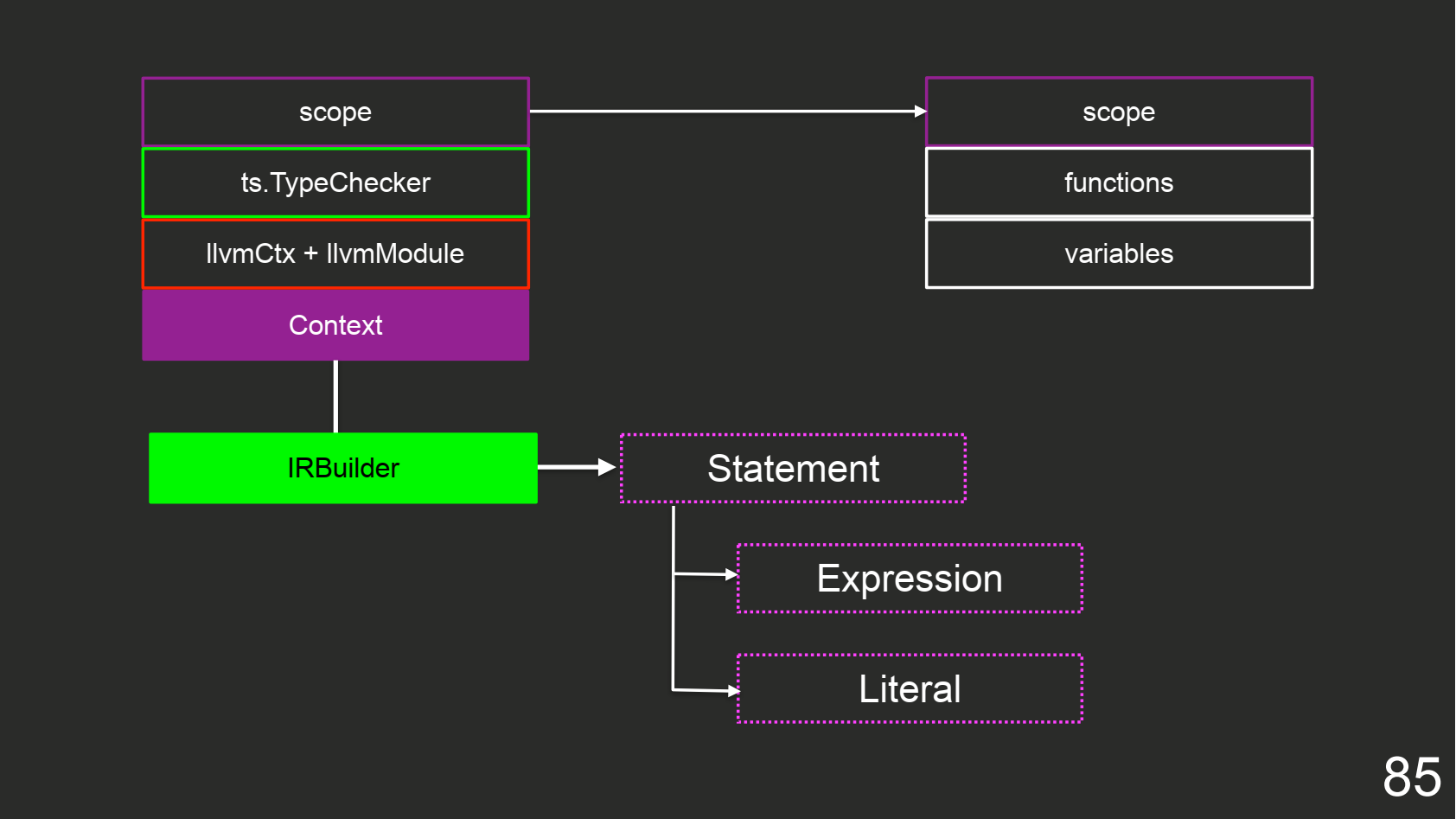
Вы пишете модуль, в котором вызываете функцию внутри этого модуля. Ее можно сгенерировать, а ниже вызывать. Поэтому мы передаем AST-ноду на представление LLVM, потому что знаем, что эта нода уже была скомпилирована, и мы можем ее вызвать.
Система типов
В JS отсутствует типизация, в TypeScript интерфейсная типизация, а в LLVM есть нативные типы. Решим проблему несовместимости типов, а для этого напишем класс, которому отдаем тип TypeScript, взятый из TypeChecker и получаем нативный тип. Если подробнее, то класс определяет, как использовать полученные данные, и генерирует обертку NativeType, чтобы завернуть туда вычисленный LLVM-тип и ряд своих флагов:
export class NativeTypeResolver { static getType(type: ts.Type, ctx: Context): NativeType|null { if (type.isNumberLiteral()) { return new NativeType( llvm.Type.getDoubleTy( ctx.llvmContext ) ); } // Магия } }
К примеру, тип внутри Number (как правило, 64-битное нецелое число) завернем в Double, которое как раз сматчится внутри LLVM.
Чтобы добавить примитивные типы, я создал новый тип, по сути int8, который является объектом:
declare type int8 = {}; declare type int16 = {}; declare type int32 = {}; declare type int64 = {}; declare type int128 = {};
На вот проблема: в TypeScript правит структурная типизация. Если сделать интерфейс «животное», он будет подходить как к кошке, так и к собаке, а тут нужно писать простые примитивные типы, а не объекты (проблема “ кошечки и собаки” в структурной типизации). Есть ссылка, по которой сказано, как сделать примитивные типы внутри TypeScript, но это показалось хардкорно для меня.
Runtime
Библиотека Runtime предоставляет API для всех слинкованных модулей программы, который постоянно будет использовать модули внутри вашей программы.
Наш компилятор состоит из двух частей — фронтенда и бэкенда. Фронтенд на TypeScript, а бэкенд генерирует IR-код. Чтобы написать Runtime-библиотеку на С++, нам нужно обучить фронтенд работать с теми функциями, которые есть внутри Runtime. Поэтому создаем файл runtime.d.ts:
///
Объявим в Runtime-библиотеке функцию console_log для поддержки типов number, string и boolean. Нам это нужно, так как в TypeScript есть overloading, а мы используем примитивную типизацию.
Напишем реализацию функции на C++:
LIBRARY_EXPORT void console_log(double number) { puts(number2string(number)); } LIBRARY_EXPORT void console_log(const char *str) { puts(str); } LIBRARY_EXPORT void console_log(bool boolean) { if (boolean) { puts("true"); } else { puts("false"); } }
Когда мы печатаем число, то сначала мы переводим его в строку с помощью функции number2string() и печатаю ее с помощью puts(). Для строки используем стандартную функцию puts(), а для boolean печатаем константную строку «true», если значение равно true, и «false», если значение равно false.
Подобная перегрузка внутри C++ возможна благодаря технике name mangling (или name decoration). Рассмотрим программу на нашем StaticScript, которая печатает число, boolean и строку:
console_log(1.0); console_log(true); console_log("str");
И рассмотрим сгенерированный IR-код программы:
@0 = private constant [4 x i8] c”str\00" define i64 @main() { entry: call void @_Z11console_logd(double 1.000000e+00) call void @_Z11console_logb(i1 true) call void @_Z11console_logPKc(i8* getelementptr …) ret i64 0 } declare void @_Z11console_logd(double) declare void @_Z11console_logb(i1) declare void @_Z11console_logPKc(i8*)
Чтобы распечатать double, она использует функцию _Z11console_logd().
Также мы провели декларацию функций, потому что программа состоит из разных модулей, и в Си-подходе есть header-файлы для работы с этой функцией. Так как у нас нет header-файлов, мы сгенерировали декларацию вручную.
Берем наш d.ts, переводим его в C++-код и генерируем внутрь, как работать с этой функцией.
Объекты и классы компилятора
Рассмотрим, как реализовать объекты и классы в нативном компиляторе и как это работает в V8. Для этого опять берем d8, запускаем с флагом --allow-natives-syntax и печатаем объект:
%DebugPrint({0: false, 1: true, a: “holyjs”});
В JS всё представляется в виде объекта, и любой объект может быть массивом. У объекта есть тип JS_OBJECT_TYPE, kind (внутренняя оптимизация, позволяющая понимать, что мы именно храним), elements и properties:

Объект состоит из Indexed Properties и Named Properties. Например, строка «holyjs» попадет в массив с обратной map, где будет содержаться, что a соответствует «holyjs». Числа же попадут в обычный целочисленный массив.
Но тут есть проблема: если вы захотите это запустить на локальной машине и напишете 0: false, 550: true, то объект сделает аллокацию массива на 550 элементов. Поэтому если вы хотите использовать объект в качестве массива, то инкрементируйте через счетчик от 0 до бесконечности, например, через PUSH. В нашем случае мы использовали только 0 и 1, а объект аллоцировал массив размером 17, где 0 — это false, 1 — true, а всё остальное дырки.
Вторая проблема заключается в создании типизации внутри V8. В JS нет типов, и всё можно мутировать до бесконечности. Я делаю объект, а потом в каждой итерации начинаю добавлять и мутировать новое свойство:
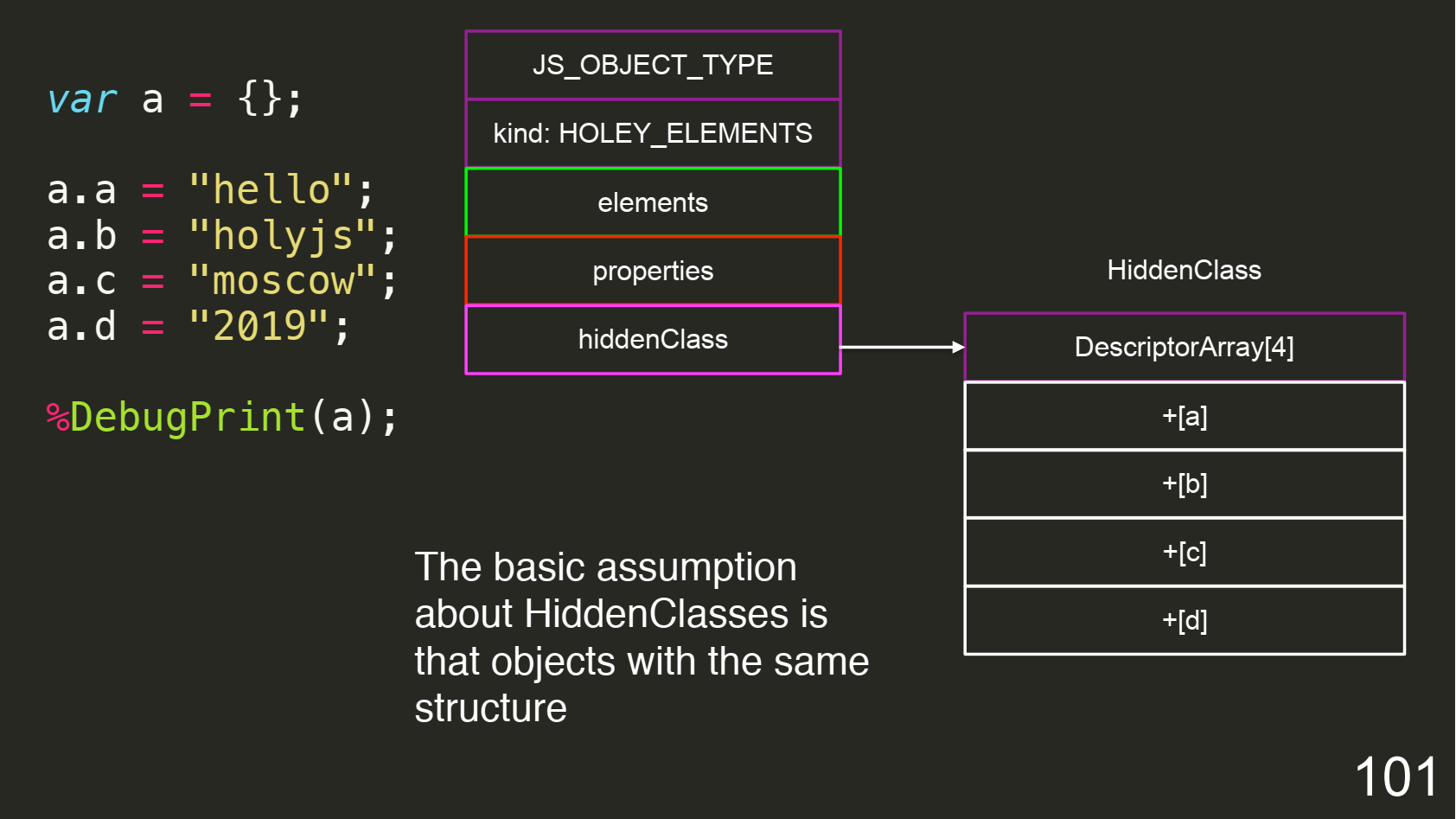
Поэтому у них есть отдельные классы hiddenClass, которые ссылаются на массив с дескрипторами. Каждый раз, когда модифицируем наш объект, мы собираем новый shape, поэтому собирается дичайший prototype chain. С каждым добавлением нового поля создается новый hiddenClass. Так как объекты могут содержаться из других объектов, это позволяет вводить типы внутри V8.
Нативные классы компилятора
Рассмотрим, как реализуются нативные классы в нативных языках программирования, где не все является объектами. Напишем на TypeScript класс User:
class User { protected name: string; protected age: number; protected weight: number; constructor(name: string, age: number, weight: number) { this.name = name; this.age = age; this.weight; } public getWeight(): number { return this.weight; } }
Мы пишем на ООП. Но в нативных языках программирования такого нет. В том же C++ классы представляют собой абстракцию поверх скрытой структуры. Поэтому C++ достаточно магический язык: можно писать любые абстракции, но они трансформируются без твоего ведома и без проблем.
Мы решили сделать класс. Нам нужна структура, описывающая участок в оперативной памяти, в котором будем сохранять значения:
struct User { char* name; double age; double weight; }; User* construct_User(char *name, double age, double weight) { // code } double getWeight(User *ptr) { return ptr->weight; }
Теперь наша программа работает с типизацией. Но как работает типизация в компьютере, ведь оперативная память не является типизированным источником? У нас есть наборы инструкций нашей программы. Эти инструкции работают с определенными типами внутри регистров. Отсюда типизация программы скрыта внутри инструкции, которую мы сгенерируем.
В LLVM тоже нет классов, поэтому там это было бы реализовано в виде некоторой структуры. А теперь нужно сделать конструктор для этой структуры. Конструктор будет уже не методом, а отдельной функцией, которая выделяет в куче структуру, куда будем сохранять конечные значения, модифицирует ее в соответствии со свойствами и возвращает указатель. Все остальные методы в низкоуровневых языках программирования работали бы с указателем этого объекта, или мы бы передавали его через стек. То есть отсутствует та самая абстракция.
Чтобы сгенерировать такую структуру, мы генерируем LLVM-тип, который является структурой, а внутрь него итерируемся по типу из TypeScript того объекта. Затем находим свойства, и конвертируем типы в LLVM-типы, используя NativeType Resolver (прослойка, которая позволяет приводить представления из TypeScript типов в LLVM-типы):
const struct = llvm.StructType.create(ctx.llvmContext, structName); struct.setBody(properties.map( (property: ts.Symbol) => { const nativeType = NativeTypeResolver.getType( ctx.typeChecker.getTypeOfSymbolAtLocation(property, node), ctx ); return nativeType.getType(); } ));
Динамическая типизация в компиляторе
{ let result; if (Math.random() > 0) { result = {}; } else { result = "string"; } console.log(result); }
Внутри позитивной ветки условия у нас объект, а внутри отрицательной — строка. Как с этим можно работать?
Воспользуемся решением, которое использует PHP, — будем хранить тип и union всех полей. В качестве типа возьмем восьмибитный enum, в котором сохраняем перечисление всех низкоуровневых типов, которые будем хранить. А значения будем хранить внутри union:
enum DynamicType: int8_t { BOOLEAN = 1, NUMBER = 2, INT64 = 3, UNDEFINED = 3, }; class Dynamic { private: DynamicType type; union { double number; bool boolean; int64_t int64; }; };
Если бы мы писали все свойства отдельно, они бы записывались последовательно друг за другом, потому что структура — это линейный участок оперативной памяти. Тогда бы у нас тип попал в 1 байт, а всё, что внутри union, выстроилось бы последовательно. Но благодаря union все типы мы упаковываем в 8 байт, потому что это размер int64. Остается 7 байт, которые можно использовать под что угодно, и размер моей структуры равен 16 байт.
V8 везде использует объект, за исключением оптимизации Smi, когда он может внутрь 64-битного адреса сохранять integer. И в последний бит V8 может сохранять «0» или «1».
«1» обозначает, что это — адрес объекта. Тогда он будет делать разыменование, прыгая и загружаясь в нужный участок памяти. «0» используется для Smi-чисел. Такой подход позволяет делать разыменование, не тратя L1, L2 кэши. Нет смысла сохранять маленькое число внутрь типа объекта из-за лишней траты оперативной памяти.
В итоге у нас есть теоретически 31 бит на 32-битную платформу. Но в реальности доступны где-то 29 бит.
Массивы в компиляторе
Массив — это тоже линейный участок памяти, где все элементы должны быть выровнены по размеру. Чтобы перейти к элементу внутри массива, мы можем использовать арифметику над указателями: взять адрес начала массива и сложить с индексом, умноженным на размер элемента. Благодаря этому трюку мы можем спокойно взять любое число за константное время.
Чтобы сделать динамический массив, используется структура, которая хранит указатель elements на часть линейной памяти, где находится массив, а также размер элемента size и количество элементов capacity:
struct Vector { void* elements; int32_t size; int32_t capacity; };
Чтобы всё работало, мы внутри scope сохраним класс Uint8Array, который map-ится на конечную структуру:
this.scope.classes.set( 'Uint8Array', ArrayLiteralExpressionCodeGenerator.buildTypedArrayStructLLVMType( llvm.Type.getInt8Ty(this.llvmContext), this, 'array
В V8 это работает похоже, только массивы в V8 хранят еще и скрытый класс, потому что массив в V8 — это объект. Также вы можете добавить любой метод для этого массива.
Нужно, чтобы все элементы массива были одного размера. Если мы захотим сделать массив на 10 тысяч элементов, внутри которого мы закинем только double, внутри элемент массива будет занимать 8 байт, потому что мы упаковываем double. Но что, если после итерации цикла мы кидаем строку?
{ let result = []; for (let i = 0; i < 10000; i++) { result.push(Math.random()) } result.push("Hehehehe Another Type"); }
Размер строки, а именно адреса объекта или его упаковки, будет отличен от размера double. Тут будет 24 байта, потому что отдельно хранится строка на объект и скрытый класс.
Такой тип хранения внутри V8 называется boxing. Из-за того, что мы используем TypeScript, на уровне фронтенда есть ограничение. А если это объект массива с любыми типами, то я просто использую динамический массив с элементами по 16 байт.

Kind
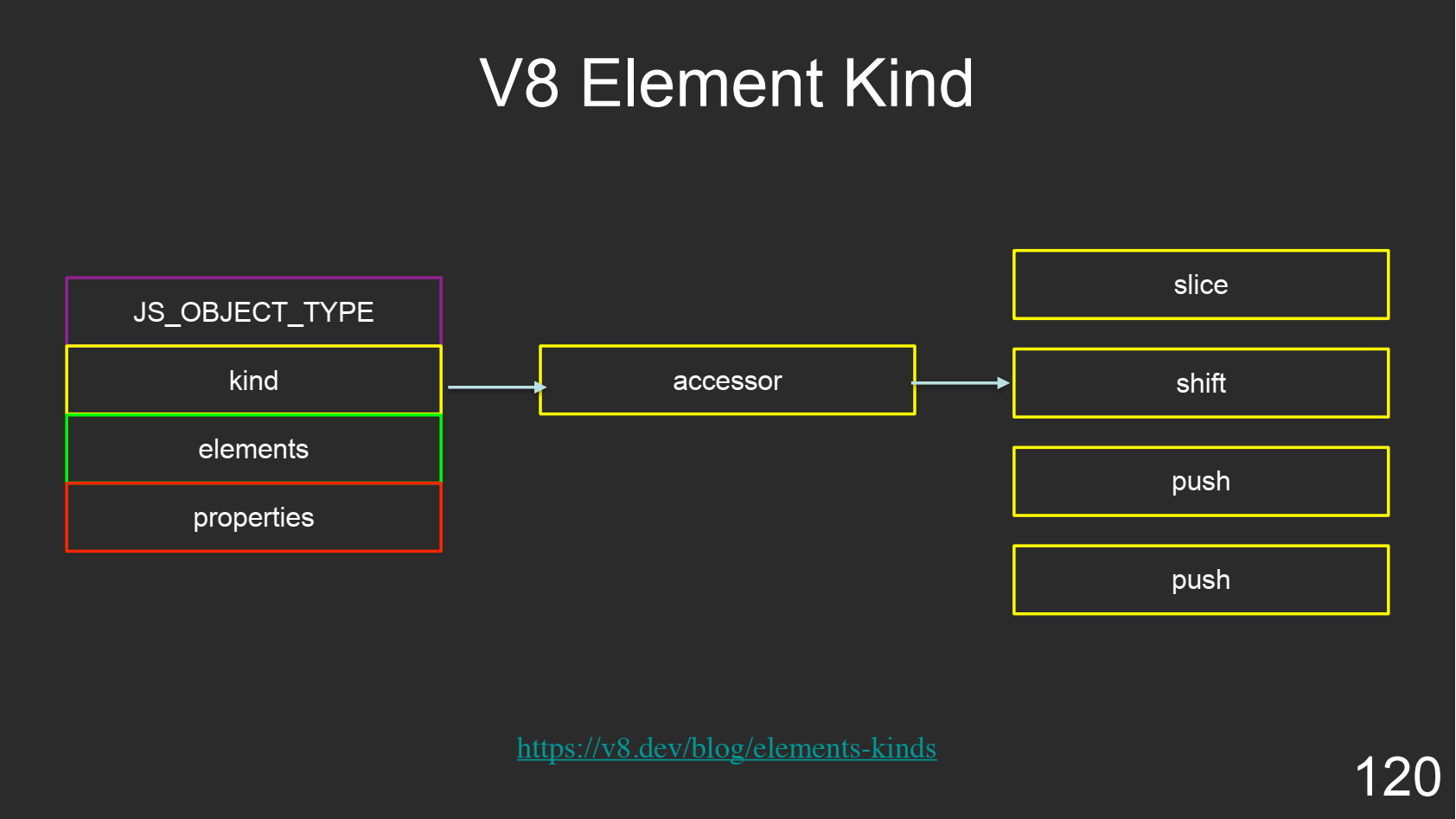
Объект может являться массивом, но при этом он может являться массивом абсолютно разных значений. Для этого в V8 есть Kind, который позволяет работать с такими массивами. Это некий подтип объекта, который позволяет взять доступы, чтобы правильно оперировать и получать смещение из этого объекта.
Финальная архитектура
Так архитектура проекта выглядит в финальном виде:
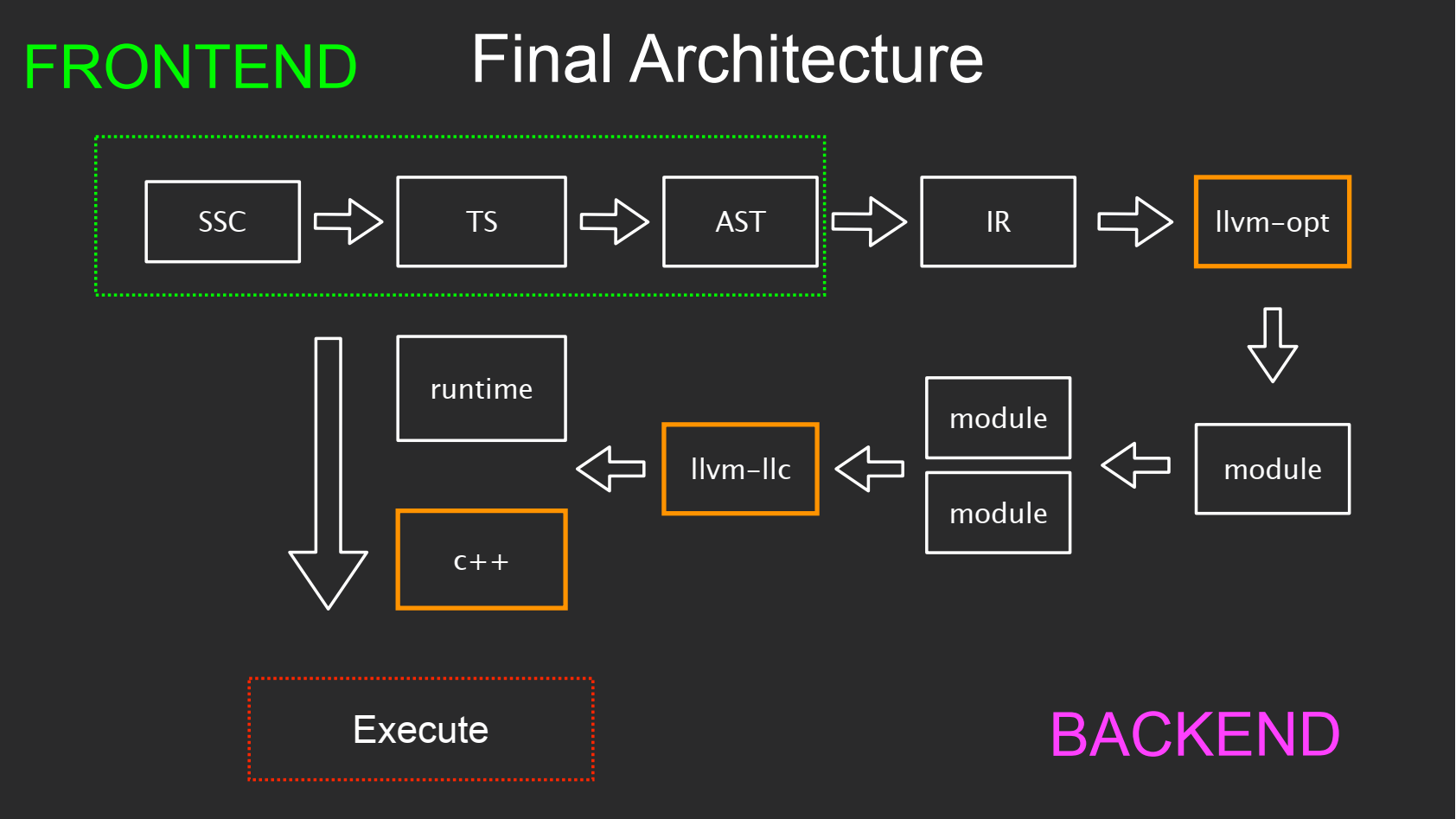
Мы закидываем TypeScript-код в SSC. Затем вызывается TypeScript-фреймворк, который весь код парсит, пре-эмитит и выполняет диагностики. На выходе из него мы получаем AST и все проверки.
Из AST мы генерируем с помощью бэкенда над бэкендом в IR-код. Далее IR-код оптимизируется в программе llvm-opt. Далее эти модули с помощью llvm-llc компилируются в объектные файлы. Теперь мы используем C++ (alias компилятора на операционной системе) и Runtime-библиотеку для линковки всех модулей программы между собой, и мы получаем исполняемые файлы.
Фронтенд на схеме выделен зеленым прямоугольником, а все остальное — бэкенд. Оранжевым на схеме показаны вызовы сторонних программ.
Итак, мы убедились, что компилятор для TypeScript возможно реализовать. Но есть одна проблема — TypeScript является суперсетом над JS. А если ограничить язык на семантике TypeScript и отказаться от динамических объектов и другой магии JavaScript, то вы просто придете к Dart первой версии.
В этом году HolyJS 2020 Piter пройдет в онлайн формате. В этот раз на конференции выступит участник core-команды Vue.js, автор нескольких опенсорс-библиотек (vue-multiselect, vuelidate and vue-global-events) Дэмиан Дулиш. Еще больше крутых спикеров можно послушать по билету-абонементу на все 8 конференций летнего сезона.