Резюме
Хотя корни глубинного обучения уходят в прошлое на десятилетия, ни сам термин «глубинное обучение», ни этот подход, не были так популярны до того момента, когда пять лет назад в эту область вдохнули новую жизнь такие работы, как уже ставшее классическим исследование от 2012 года за авторством Крижевский, Сутскевер и Хинтон о глубинной сетевой модели Imagenet (Krizhevsky, Sutskever, & Hinton, 2012).
Что в этой области было открыто за последующие годы? На фоне внушительного прогресса в таких областях, как распознавание речи, распознавание изображений и игры, а также значительного энтузиазма в популярной прессе, я хотел бы рассмотреть десять проблем глубинного обучения (ГО), и заявить, что для создания искусственного интеллекта общего назначения (ИИОН) ГО необходимо дополнять другими техниками.
1. Приближается ли ГО к своему пределу?
Большинство задач, в которых ГО предложило принципиально новые решения (зрение, речь), в 2016-2017 годах вошло в зону уменьшающейся отдачи.
Франсуа Чоле, Google, автор библиотеки для нейросетей Keras
«Прогресс науки движется от одних похорон к другим». Будущее зависит от студента, с большим подозрением относящегося к тому, что я говорю.
Джофф Хинтон, дедушка глубинного обучения
Хотя корни глубинного обучения уходят в прошлое на десятилетия, на него обращали очень мало внимания примерно до 2012 года. Но в том году поменялось решительно всё. Была опубликована серия крайне влиятельных статей — к примеру, статья авторов Крижевский, Сутскевер и Хинтон «Классификация ImageNet при помощи глубинных свёрточных нейронных сетей», добившихся передовых результатов в распознавании образов в проекте, известном, как ImageNet. Другие лаборатории уже работали над сходными проектами [Cireşan, Meier, Masci, & Schmidhuber, 2012]. Ещё до конца года ГО попало на первую страницу The New York Times и быстро стало самой известной технологией из мира ИИ. И если основная идея тренировки нейросетей, содержащих множество слоёв, была не новой, ГО впервые стало практически применимой технологией, благодаря, в частности, увеличению вычислительных мощностей и наборов данных.
С тех пор ГО привело к получению множества передовых результатов в таких областях, как распознавание образов, распознавание речи, перевод между языками, и играет важную роль в широком спектре текущих приложений. Корпорации уже инвестировали миллиарды долларов в борьбе за таланты ГО. Один из известных сторонников ГО, Эндрю Ын, даже предположил, что «если обычный человек может решить задачу, подумав над ней менее секунды, мы, вероятно, сможем автоматизировать её решение при помощи ИИ либо уже сейчас, либо в ближайшем будущем». Недавняя статья в журнале New York Times Sunday Magazine, в основном посвящённая ГО, утверждает, что технология предназначена для «переизобретения самого процесса вычислений». Однако же ГО вполне может приближаться к своему пределу, как я и предсказывал ранее, в начале возрождения этой темы, и как начали говорить такие люди, как Хинтон [Sabour, S., Frosst, N., & Hinton, G. E. (2017). Dynamic Routing Between Capsules] и Чоле [Chollet, F. (2017). Deep Learning with Python. Manning Publications] в последнее время.
Что такое ГО, и что оно продемонстрировало нам по поводу природы интеллекта? Что от него можно ожидать, и когда можно ожидать его провала? Как близко или далеко мы находимся от «искусственного интеллекта общего назначения» (ИИОН), и точки, в которой машины начнут показывать сравнимую с людьми гибкость в решении неизвестных задач? Цель этой работы — придержать иррациональный рост этой темы и рассмотреть, что нам необходимо привнести в эту область, чтобы двигать её далее.
Эта работа написана как для исследователей в данной области, так и для растущего количества потребителей ИИ, не так сильно подкованных технически, но желающих понять, куда движется эта область. Поэтому я начну с небольшого, не очень технического введения, нацеленного на то, чтобы объяснить, что у систем с ГО получается хорошо и почему (раздел 2), перед тем, как перейти к оценке слабых сторон ГО (раздел 3) и некоторых страхов, появляющихся из-за недопонимания возможностей ГО (раздел 4), а потом закончу на перспективах движения вперёд (раздел 5).
ГО вряд ли исчезнет, да это и не нужно. Но после пяти лет с момента возрождения области неплохо критически осмотреть достижения, а также то, чего ГО не смогло достичь.
2. Что такое глубинное обучение и что у него получается хорошо
ГО в первую очередь — статистическая техника классификации закономерностей на основе пробных данных с использованием многослойных нейросетей.
Нейросети, описываемые в литературе по ГО, обычно состоят из набора модулей ввода, принимающих такие данные, как пиксели или слова, множества скрытых слоёв (чем больше слоёв, тем глубже сеть), содержащих скрытые модули (известные также, как узлы или нейроны), и набора модулей вывода, с учётом наличия связей между различными узлами. В типичном случае такую сеть можно натренировать, например, на большом наборе написанных от руки цифр (это входные данные в виде изображений) и меток (выходные данные), определяющих категории, к которым принадлежат входные данные (это изображение — 2, это — 3, и так далее).
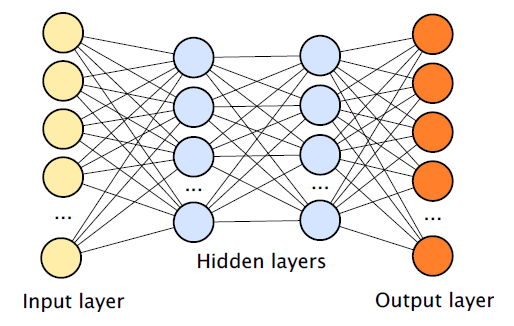
Со временем алгоритм обратного распространения ошибки позволяет процессу под именем градиентный спуск подправлять связи между модулями так, чтобы любые входные данные приводили к выдаче соответствующих выходных данных.
В целом связь между вводом и выводом, которую изучает сеть, можно представлять себе как построение карты соответствия. Нейросети, особенно имеющие множество скрытых слоёв, очень хорошо справляются с построением соответствия между вводом и выводом. Эти системы обычно описывают как нейросети, поскольку модули для ввода, скрытые модули и модули для вывода можно представлять себе в виде приблизительных моделей биологических нейронов, пусть и чрезвычайно упрощённые, а связь между модулями некоторым образом представляет связи между нейронами. Давний вопрос, находящийся за пределами данной работы, касается степени биологической достоверности подобных искусственных нейросетей.
Большая часть ГО-сетей использует технологию под названием «свёртка», ставящую такие ограничения на связи сети, что у них естественным образом появляется такое свойство, как трансляционная инвариантность. По сути, эта идея состоит в том, что объект может перемещаться по изображению, не теряя своей идентичности; круг в верхнем левом углу можно признать тем же самым объектом, что и круг в правом нижнем углу (даже без наличия прямых тому доказательств).
Глубинное обучение также известно способностью самостоятельно выстраивать промежуточные репрезентации — к примеру, внутренние модули, реагирующие на такие вещи, как горизонтальные линии или более сложные элементы изображения. В принципе, с бесконечным количеством данных ГО-системы могут справиться с любым конечным детерминистским сопоставлением между любыми наборами ввода и соответствующего вывода, хотя на практике их способность обучиться определённому сопоставлению зависит от многих факторов. Одна из распространённых проблем — угодить в локальный минимум, в котором система застревает с не совсем оптимальным решением, когда лучшего решения нет в числе близлежащих решений. На практике результаты с большими наборами данных обычно получаются неплохими, причём на широком круге потенциальных сопоставлений.
К примеру, в области распознавания речи нейросеть учиться сопоставлять набор звуков речи и набор меток (слов или фонем). При распознавании образов нейросеть учится сопоставлять набор изображений набору меток (к примеру, изображения машин отмечаются, как машины). В системе игры в Atari, разучиваемой сетью DeepMind, нейросети разучивают соответствие между пикселями и позициями джойстика.
Системы ГО чаще всего используются как классификационные, в том смысле, что миссия типичной сети — это решения по поводу того, к какому набору категорий (определяемому выходными модулями нейросети) принадлежит данный ввод. Используя воображение, можно представить, что возможности классификации огромны — вывод может представлять собой слова, координаты на доске для игры в го, да и практически что угодно ещё. В мире бесконечных данных и бесконечных вычислительных ресурсов вряд ли понадобятся другие технологии.
3. Границы возможностей ГО
Границы ГО начинаются с отрицания: мы живём в мире, в котором не бывает бесконечных данных. Системы, полагающиеся на ГО, часто должны заниматься обобщением за пределами определённых виденных ими данных — будь то новое произношение слова или изображение, отличающееся от того, что система уже видела до этого. Там, где данных не бесконечно много, возможности формальных доказательств, гарантирующих высокое качество работы, ограничены.
Как позже обсуждается в статье, обобщение бывает двух видов — интерполяция между двумя известными примерами, и экстраполяция, требующая выхода за пространство известных тренировочных примеров. Чтобы нейросети хорошо обобщали, им обычно требуются большие объёмы данных, а тестовые данные должны походить на тренировочные — так, чтобы новые ответы были интерполяциями между старыми. В работе Крижевского, Сацкевера и Хинтона свёрточную нейросеть с девятью слоями, 60 млн параметров и 650 000 узлов тренировали на миллионе различных примеров, разбитых по тысяче категорий.
Такой подход с использованием грубой силы хорошо работал в сильно ограниченном мире ImageNet, где все стимулы можно развести по относительно небольшому набору категорий. Также он хорошо работает в стабильных областях вроде распознавания речи, в которых образцы неизменным образом сопоставляются с ограниченным набором категорий звуков речи — но по многим причинам ГО нельзя рассматривать (как это иногда делают в популярной прессе) в качестве общего решения ИИ.
Вот десять проблем, стоящих на пути современных ГО-систем.
3.1 ГО нуждается в данных
Люди способны выучить абстрактные связи за несколько раз. Если я скажу вам, что «шместра» — это сестра возрастом от 10 до 21 года, дав вам единственный пример, вы сразу зе сможете вычислить, если ли у вас шместра, есть ли она у вашего лучшего друга, есть ли она у ваших детей или родителей, и так далее. (Скорее всего, у ваших родителей её уже нет, если даже и была, и это вы тоже могли бы довольно быстро понять).
Обучаясь понятию «шместры», в этом случае — через чёткое определение, вы полагаетесь не на сотни тысяч или миллионы тренировочных примеров, но на возможности представлять абстрактные связи между переменными, похожими на алгебраические. Люди способны выучивать подобные абстракции, как через точное определение, так и через менее явные. Даже семимесячные младенцы способны на это — они выучивают абстрактные правила, похожие на язык, на основе небольшого количества непомеченных примеров всего за пару минут (Marcus, Vijayan, Bandi Rao, & Vishton, 1999). Последующая работа (Gervain and colleagues 2012) показывает, что младенцы способны на похожие вычисления. У ГО сейчас нету механизма для выучивания абстракций через непосредственное определение, данное вслух, и оно работает лучше с тысячами, миллионами или даже миллиардами тренировочных примеров, как делала DeepMind с играми Atari. Как утверждают Бренден Лэйк [Brenden Lake] с коллегами в нескольких недавних работах, люди гораздо эффективнее выучивают сложные правила, чем системы ГО (Lake, Salakhutdinov,
& Tenenbaum, 2015; Lake, Ullman, Tenenbaum, & Gershman, 2016). На эту тему можно посмотреть ещё работу (George et al 2017), и мою собственную работу со Стивеном Пинкером по чрезмерному упорядочиванию ошибок у детей по сравнению с нейросетями (Marcus et al., 1992).
Джофф Хинтон также беспокоился по поводу того, как ГО полагается на большое количество размеченных примеров, и выражал свои опасения в недавней работке по капсюльным сетям со своими соавторами (Sabour et al., 2017), отмечая, что свёрточные нейросети (самая популярная архитектура ГО) может встретиться с «экспоненциальной неэффективностью, которая может стать причиной их гибели. Хороший кандидат — это трудности, с которыми сталкиваются свёрточные сети при обобщениях, связанных с новыми точками зрения (например, вид на объект с другой перспективы при визуальном распознавании образов). Возможность справляться с трансляционной инвариантностью в них встроена, но при других типичных трансформациях нам приходится выбирать между воспроизводством детекторов особенностей, расположенных на экспоненциально растущей решётке и увеличением размера размеченного тренировочного набора сходным экспоненциальным образом».
В задачах с ограниченным набором данных ГО часто не является идеальным решением.
3.2 Глубинное обучение пока что имеет небольшую глубину и плохо переносит полученные знания на другие данные
Хотя ГО способно на некоторые весьма удивительные вещи, важно понимать, что слово «глубинное» относится к его технической, архитектурной особенности (большому количеству скрытых слоёв, используемому в современных нейросетях, поскольку их предшественники использовали только один слой), а не к концептуальной (репрезентации, выстраиваемые в этих сетях, нельзя естественным образом применить к каким-либо абстрактным понятиям вроде «правосудия», «демократии» или «интервенции»).
Даже более призёмлённые вещи вроде «мячик» или «противник» могут оказаться недоступными для сети. Рассмотрим пример работы DeepMind с играми Atari и обучением с подкреплением, комбинирующим ГО с подкреплением (обучаемый пытается добиться максимальной награды). Результаты, якобы, фантастические: система играет наравне или обыгрывает людей-экспертов на широком круге игр, используя единый набор «гиперпараметров», управляющих такими свойствами, как скорость изменения весов в сети, и не обладая предварительными знаниями о конкретных играх и об их правилах. Но эти результаты легко интерпретировать совершенно неверно. К примеру, согласно одному из широко распространившихся видео о том, как система обучается игре в Breakout, «после 240 минут тренировки система поняла, что организация туннеля в стене — наиболее эффективный путь достижения победы».
Но система ничего такого не поняла, она вообще не понимает, что такое туннель и что такое стена. Она просто выучила определённые действия для определённых ситуаций. Тесты с переносом — в которых систему ГО с подкреплением ставят в ситуации, немного отличающиеся от тех, на которых система тренировалась, показывает, что ГО-решения часто оказываются искусственными. К примеру, команда исследователей из Vicarious показала, что более продвинутый потомок Atari system, A3C [Asynchronous Advantage Actor-Critic] не справился с различными некритичными изменениями в игре Breakout (Kansky et al., 2017), такими, как изменение вертикального положения платформы, отбивающей мяч, или появление стены в середине экрана. Из этих демонстраций становится ясно, что нельзя присваивать системе, использующей ГО с подкреплением, способности понять, что такое платформа или что такое мяч. Такие заявления в сравнительной психологии называют ошибкой атрибуции. Дело не в том, что Atari system на самом деле каким-то образом поняла концепцию стены — система просто искусственным образом пробилась сквозь стену в рамках небольшого набора условий, на которые она была натренирована.
Моя собственная команда исследователей из стартапа Geometric Intelligence (позже купленного компанией Uber) обнаружила сходные результаты в контексте игры в слалом. В 2017 команда исследователей из Беркли и OpenAI показала, что в других играх несложно создать сходные состязательные примеры, сбивающие с толку не только оригинальный алгоритм DeepMind, DQN, но и его последователя A3C и несколько других сходных технологий (Huang, Papernot, Goodfellow, Duan, & Abbeel, 2017).
Недавние эксперименты (Robin Jia and Percy Liang, 2017) приходят к тому же выводу в другой области: работе с языком. Различные нейросети были натренированы на поиск ответов на вопросы в задаче, известной как SQuAD (Stanford Question Answering
Database), в которой целью служит подсветка слов в определённой фразе, соответствующих заданному вопросу. К примеру, в одном случае натренированная система впечатляюще правильно, определила квотербека из выигравшей Суперкубок XXXIII команды, как Джона Элвея, на основе изучения небольшого параграфа. Но Джиа и Лиян показали, что простая вставка отвлекающих от темы предложений (например, о якобы случившейся победе Джеффа Дина в другой игре серии) привела к обрушению качества работы системы. У 16 моделей медианные показатели успеха упали с 75% до 36%.
Как это часто и бывает, извлечённые при помощи ГО закономерности оказались гораздо более искусственными, чем это кажется первоначально.
3.3 У ГО пока нет естественного способа работы с иерархической структурой
Лингвист Ноам Хомский не удивился бы проблемам, описанным Джиа и Лияном. По сути большинство текущих языковых моделей на базе ГО представляют себе предложения в виде последовательностей слов, при том, что Хомский давно говорит, что язык имеет иерархическую структуру, в которой более крупные построения рекурсивно составляются из более мелких. К примеру, в предложении «подросток, ранее пересекший Атлантику, установил рекорд кругосветных полётов» основным простым предложением в составе сложного будет «подросток, установивший рекорд кругосветных полётов», а в него будет встроено дополнительное предложение «ранее пересекший Атлантику», уточняющее, какой именно подросток.
В 80-х годах в одной работе (Fodor and Pylyshyn, 1988) были описаны сходные проблемы, связанные с более ранними версиями нейросетей. В своей работе (Marcus, 2001) я предположил, что простые рекуррентные сети (SRN — предшественник современных более сложных ГО-сетей, известных, как RNN) с трудом смогут систематически представлять и расширять рекурсивную структуру различных видов незнакомых им предложений.
А в 2017-м году учёные (Brenden Lake and Marco Baroni, 2017) проверили, соответствуют ли до сих пор эти пессимистические предположения действительности. Как они написали в заголовке работы, современные нейросети «после всех этих лет всё ещё не систематичные». RNN могут «неплохо обобщать данные при небольших различиях в тренировочных и проверочных данных, но когда обобщение требует систематических композиционных навыков, RNN с треском проваливаются».
Те же самые проблемы могут появляться и в других областях, например, при планировании или при управлении моторикой, в которых необходима работа со сложной иерархической структурой, в особенности, если система обречена сталкиваться с новыми ситуациями. Непрямые свидетельства таких ситуаций можно увидеть в проблемах с переносом игр Atari, упомянутых выше, а в более общем случае — в области робототехники, в которой системы обычно не справляются с обобщением абстрактных планов в необычных ситуациях.
Основной проблемой на сегодня остаётся то, что ГО выучивает корреляции между набором особенностей, которые сами по себе «плоские», неиерархичные — что-то вроде простого, неструктурированного однорангового списка. Иерархическая структура (к примеру, синтаксические деревья, отделяющие основные и подчинённые предложения) в таких системах не представляются ни напрямую, ни внутренне. В результате ГО-системы вынуждены использовать наборы различных посредников, оказывающихся в итоге неадекватными — к примеру, позиция слова в предложении по порядку от начала.
Такие системы, как Word2Vec (Mikolov, Chen, Corrado, & Dean, 2013), представляющие отдельные слова в виде векторов, достигают скромных успехов. Некоторые системы, использующие хитроумные трюки, пытаются представлять полные предложения в векторных пространствах, пригодных для ГО (Socher, Huval, Manning, & Ng, 2012). Но, как чётко продемонстрировали эксперименты Лэйка и Барони, рекуррентные сети так и остаются ограниченными в своих возможностях достоверно представлять и обобщать богатые структуры.
3.4 ГО до сих пор с трудом работает с неточно определяемыми понятиями
Если вы не можете объяснить такие нюансы, как разница между «Джон пообещал Мэри уйти» и «Джон пообещал уйти от Мэри», вы не можете сделать выводы по поводу того, кто от кого уходит и что будет дальше. Сегодняшние машинные читающие системы достигли некоторого успеха в таких задачах, как SQuAD, где ответ на данный вопрос непосредственно содержится в тексте, но гораздо меньшего успеха в задачах, в которых выводы выходят за пределы того, что содержится в тексте — благодаря комбинированию либо нескольких предложений (многозначные выводы), либо комбинации предложений с дополнительными знаниями, которые не обозначены в данной выборке текста. Люди при чтении текста часто делают достаточно широкие выводы, не следующие из текста, на основе того, что упомянуто лишь косвенно — к примеру, выводы о характере персонажа, сделанные на основе непрямого диалога.
И хотя работы Боумэна с коллегами (Bowman, Angeli, Potts, & Manning, 2015; Williams,
Nangia, & Bowman, 2017) сделали несколько важных шагов в этом направлении, в настоящее время не существует ГО-системы, способной делать неочевидные выводы на основе знаний о реальном мире с точностью, хоть как-то приближающейся к человеческой.
3.5 ГО до сих пор недостаточно прозрачно
Относительная прозрачность нейросетей, работающих по принципу «чёрного ящика», является одной из основных тем, обсуждаемых в последние несколько лет (Samek, Wiegand, & Müller, 2017; Ribeiro, Singh, & Guestrin, 2016). В текущей реализации ГО-системы обладают миллионами и даже миллиардами параметров, определяемых разработчиками не в виде каких-то человекочитаемых списков переменных, используемых каноническими программистами (типа “last_character_typed”), а в виде их географии в рамках сложной сети (значение активности узла i в слое j в сетевом модуле k). Хотя для визуализации вкладов отдельных узлов сети в сложных сетях были сделаны определённые шаги (Nguyen, Clune, Bengio, Dosovitskiy, & Yosinski, 2016), большинство наблюдателей признают, что нейросети в целом остаются «чёрными ящиками».
Какое это имеет значение в долгосрочной перспективе, остаётся непонятным (Lipton, 2016). Если системы сами по себе достаточно надёжны и самостоятельны, это может и не иметь значения; если важно использовать их в контекстах более сложных систем, для возможности поиска ошибок это может быть критичным.
Проблема прозрачности, не решённая до сих пор, является потенциальной уязвимостью при использовании ГО в таких областях, как финансовые сделки или медицинские диагнозы, в которых использующие их люди хотели бы понять, как именно данная система пришла к данному решению. Как указала Катерина О'Нил (2016), такая непрозрачность также может привести к серьёзным искажениям.
3.6 ГО пока что плохо интегрируется с уже существующими знаниями
Основным подходом к ГО является интерпретационный, то есть, самодостаточный и изолированный от остальных собранных знаний, которые в принципе могли бы быть полезными. Работа с ГО состоит в том, чтобы найти тренировочную базу данных — набор вводных данных, связанный с соответствующими выходными данными — и научить сеть всему, что требуется для решения задачи, выучивая взаимосвязи между входными и выходными данными при помощи хитрых архитектурных вариантов, а также технологий для очистки и дополнения набора данных. Применение предыдущих знаний, имеющихся по данной задаче, за редким исключением (например, свёрточные ограничения сетей, LeCun, 1989), минимизировано.
Таким образом, например, система, используемая в работе Лерера с коллегами (Lerer et al, 2016), пытающаяся обучиться физике падающих башен, не имеет предыдущих знаний по физике (кроме того, что определено в свёртке). Законы Ньютона не вшиваются в её программу, вместо этого система строит их приближение (в рамках определённых ограничений), изучая последствия на основе сырых пиксельных данных. Как я отмечаю в своей следующей работе, исследователи ГО страдают от когнитивного искажения, запрещающего использовать предыдущие знания, даже когда они отлично известны (как это происходит в случае с физикой).
Также неясно, как можно интегрировать имеющиеся знания в ГО-систему в общем случае; в частности из-за того, что знания, представленные в таких системах, в основном сводятся к (по большей части непрозрачным) корреляциям между особенностями, а не к абстракциям количественных постулатов (таких, как, например «все люди смертны»).
Связанная с этим проблема произрастает из культуры, сложившейся в области МО, поощряющей соревнования в области решения самодостаточных, замкнутых проблем, не требующих общих знаний. Эту тенденцию хорошо демонстрирует платформа для соревнований по МО под названием Kaggle, где участники соревнуются на получение лучших результатов на заданном наборе данных. Всё, что им нужно для решения задачи, аккуратно собрано и упаковано, вместе со всеми соответствующими файлами для входных и выходных данных. В таких случаях достигнут отличный прогресс — распознавание речи и некоторые особенности распознавания изображений в принципе можно решить по парадигме Kaggle.
Проблема, однако, состоит в том, что жизнь — это не соревнование Kaggle; дети не получают всех необходимых им данных, аккуратно размещённых в одной директории диска. Обучение в реальном мире предполагает гораздо более случайное поступление данных, а задачи никто аккуратно не упаковывает. ГО отлично работает с такими задачами, как распознавание речи, где есть множество снабжённых метками примеров, но вряд ли кому-то известно, как применять ГО к проблемам с нечёткими параметрами. Как лучше всего починить велосипед, которому в спицы попала верёвка? По какой специальности мне идти на диплом, по математике или нейробиологии? Никакой набор тренировочных данных не даст нам ответов.
Проблемы, меньше связанные с категоризацией и больше — со здравым смыслом лежат вне области применимости ГО, и пока, насколько мне известно, ГО мало что может предложить для решения подобных проблем. В недавнем обзоре здравого смысла мы с Эрни Дейвисом начали с набора простых выводов, которые люди могут легко сделать без всякой прямой тренировки — например, кто выше, принц Уильям или его сын-младенец принц Джордж? Можно ли сделать салат из синтетической футболки? Если воткнуть булавку в морковку, где появится дырка — в морковке или в булавке?
Насколько мне известно, никто не пытался браться за такого рода задачи при помощи ГО. Такие, на первый взгляд, простые задачи, требуют от человека интегрированного знания из несопоставимых источников, поэтому они так далеко отстоят от уютного мира классификаций ГО. Они заставляют подумать о том, что для достижения человеческого уровня когнитивной гибкости наряду с ГО требуются инструменты совершенно другого рода.
3.7 ГО пока что не способно автоматически отличать причинно-следственную связь от корреляции
То, что причинно-следственная связь не есть синоним корреляции — это трюизм, однако это различие серьёзно волнует специалистов в области ГО. Грубо говоря, ГО выучивает сложные корреляции между входными и выходными особенностями, но не строит репрезентации причинно-следственных связей. ГО может легко выучить корреляцию роста и объёма словарного запаса в популяции, но ему будет не так-то просто представить способ, которым эта корреляция выводится из роста и развития людей (дети, вырастая, разучивают всё больше слов, но это не значит, что они растут из-за разучивания слов). Причинно-следственная связь была основой в некоторых других подходах к созданию ИИ (Pearl, 2000), но, вероятно, ГО не приспособлено к таким задачам, и решать их в этой области практически никто не пытался.
3.8 ГО представляет по большей части стабильный мир, причём так, что это в некоторых случаях может представлять проблемы
Логика ГО такова, что она, скорее, будет хорошо работать в очень стабильных мирах — например, в настольной игре го, правила которой не меняются, и хуже работать в таких постоянно изменяющихся системах, как политика и экономика. Касаемо применения ГО для таких задач, как предсказание стоимости акций, есть большая вероятность, что этот подход повторит судьбу проекта Google Flu Trends, изначально отлично предсказывавшего эпидемиологические данные по поисковым запросам, а потом совершенно пропустившего такие вещи, как пик сезона гриппа 2013 года (Lazer, Kennedy, King, & Vespignani, 2014).
3.9 ГО пока что хорошо работает в роли аппроксимации, но его ответам часто нельзя полностью доверять
Частично в результате других описанных в этой секции проблем, ГО-системы хорошо работают на большой части задач выбранной области, однако их легко обмануть.
Растущий набор работ демонстрирует эту уязвимость — от лингвистических примеров Джиа и Лияна, упомянутых выше, до широкого спектра демонстраций в области компьютерного зрения, когда ГО-системы путают изображения, раскрашенные в жёлто-чёрные полосы со школьными автобусами (Nguyen, Yosinski, & Clune, 2014), а заклеенные наклейками указатели парковки с хорошо набитыми холодильниками (Vinyals, Toshev, Bengio, & Erhan, 2014) — при том, что в остальных случаях результаты работы выбранных систем впечатляют.
Из недавних ошибок можно упомянуть слегка повреждённые знаки «стоп» из реального мира, которые система спутала со знаками ограничения скорости (Evtimov et al., 2017), и распечатанные на 3D-принтере черепашки, которых спутали с ружьями (Athalye, Engstrom, Ilyas, & Kwok, 2017). В недавних новостях промелькнула история о проблемах британской полиции, чья система с трудом отличала изображения обнажённых тел от песчаных дюн.
Возможность обмануть ГО-систему, вероятно, впервые была упомянута в работе Цегеды (Szegedy et al, 2013). Четыре годя спустя, несмотря на активную исследовательскую деятельность, никакого надёжного решения этой проблемы не было найдено.
3.10 Глубинное обучение тяжело использовать в прикладных целях
Ещё один факт, следующий из всех упомянутых проблем — ГО не подходит для надёжного решения прикладных задач. Как писала команда авторов из Google в 2014-м, в заголовке важного эссе, на которое так и не было получено ответа (Sculley, Phillips, Ebner,
Chaudhary, & Young, 2014), МО — это «кредитная карточка с технической задолженностью и высокими процентами», что означает, что делать системы, работающие на ограниченном наборе условий довольно легко (достижение краткосрочных целей), но очень сложно гарантировать, что они будут работать в других условиях с неизвестными данными, которые могут не походить не предыдущие тренировочные данные (долгосрочные цели, особенно когда одна система используется в качестве элемента другой, более крупной).
В важном докладе на ICML Леон Ботто в 2015-м сравнил МО с развитием мотора самолёта, и отметил, что хотя разработка самолётов основывается на построении сложных систем из множества простых, для которых возможно получить гарантии надёжной работы, МО не хватает способности давать схожие гарантии. Как отметил Питер Норвиг из Google в 2016-м, МО не хватает инкрементальности, прозрачности и возможности поиска ошибок, присущих классическому программированию, и в МО определённая простота работы меняется на наличие серьёзных проблем с надёжностью.
Хендерсон с коллегами недавно расширили это мнение, сконцентрировавшись на ГО с подкреплением, и отметив несколько серьёзных проблем в областях, связанных с надёжностью и воспроизводимостью (Henderson et al., 2017).
Хотя в автоматизации процесса разработки МО-систем был достигнут определённый прогресс (Zoph, Vasudevan, Shlens, & Le, 2017), сделать ещё предстоит очень много.
3.11 Обсуждение
Конечно же, глубинное обучение, само по себе — это просто математика; описанные выше проблемы появляются не потому, что лежащая в основе ГО математика где-то ошибается. В целом ГО — прекрасный способ оптимизации сложных систем для репрезентации взаимосвязей между входными и выходными данными на достаточно большом наборе данных. Реальная проблема состоит в непонимании того, для чего ГО подходит хорошо, а для чего — не подходит. Техника отлично справляется с проблемами чёткой классификации, в которых широкий спектр потенциальных сигналов необходимо разметить по ограниченному количеству категорий, учитывая, что система хватает данных, а проверочный набор сильно напоминает тренировочный.
Но отклонения от этих предположений могут привести к проблемам; ГО — это всего лишь статистическая технология, а все статистические технологии страдают от отклонения от первоначальных предположений.
ГО-системы работают уже не так хорошо, если данных для тренировки оказывается не очень много, или если проверочный набор отличается в важных вещах от тренировочного, или если набор проверочных примеров широк и наполнен совершенно новыми вещами. А некоторые проблемы в реальном мире вообще нельзя отнести к проблемам классификации. К примеру, к пониманию естественного языка нельзя подходить, как к задаче классификационного построения соответствия между большим конечным набором предложений и большим, конечным набором других предложений. Это, скорее, разметка соответствия между потенциально бесконечным набором входящих предложений, и таким же по объёму набором смыслов, многие из которых могли ранее не встречаться. В такой задаче ГО становится квадратным колышком, который забивают в круглое отверстие — грубым приближением в случае, когда решение должно находиться где-то в другом месте.
Один хороший способ интуитивно понять, почему чего-то не хватает — это рассмотреть набор экспериментов, проведённых мною в 1997 году, когда я проверял некие упрощённые аспекты разработки языков на классе нейросетей, который тогда был популярным в когнитивистике. Винтажные сети 1997 года были, конечно, проще сегодняшних моделей — они не использовали более трёх слоёв (входные узлы соединены со скрытыми узлами, соединёнными с выходными), и им не хватало свёрточных технологий. Но они тоже работали с обратным распространением ошибок, как сегодняшние, и так же зависели от тренировочных данных.
В языке главное — это обобщение. Как только я услышу предложение вида «Джон пилкнул мяч Мэри», я могу сделать вывод, что грамматически корректно будет сказать, что «Джон пилкнул Мэри мяч, а Элиза пилкнула мяч Алеку». Точно так же, сделав вывод о том, что означает слово «пилкнуть», я смогу понять смысл будущих предложений, даже если я не слышал их ранее.
Сводя широкий спектр проблем языка к простому примеру, который, как мне кажется, всё ещё актуален и сегодня, я провёл серию экспериментов, в которых тренировал трёхслойные перцептроны (на сегодняшнем жаргоне — полностью связанные, без свёрток) на функцию идентичности, f(x) = x, то есть, например, f(12)=12.
Тренировочные примеры были представлены набором входных узлов (и соответствующих выходных), представлявших номера в виде двоичных чисел. Число 7, к примеру, представлялось включением входных (и выходных) узлов, представляющих 4, 2 и 1. В качестве проверки обобщения я тренировал сеть на различных наборах чётных чисел, а проверял на всех возможных данных, как чётных, так и нечётных.
Каждый раз, когда я проводил эксперимент с широким набором параметров, результат получался одним и тем же: сеть (если не застревала в локальном минимуме) правильно применяла функцию идентичности к чётным числам, которые встречала раньше (допустим, 2, 4, 8 и 12), и к некоторым другим чётным числам (допустим, 6 и 14), но не справлялась ни с одним нечётным числом, выдавая, к примеру, f(15) = 14.
В целом, проверенные мною нейросети могли выучивать тренировочные примеры и интерполировать их на проверочные примеры, находящиеся в облаке точек, окружающем эти примеры в n-мерном пространстве (названном мною тренировочным пространством), но не могла экстраполировать за пределы тренировочного пространства.
Нечётные числа находились вне тренировочного пространства, и сеть не могла обобщить идентичность за пределы этого пространства. Увеличение количества скрытых узлов не помогало, как и увеличение количества скрытых слоёв. Простые многослойные перцептроны просто не могли строить обобщения за пределы тренировочного пространства (Marcus, 1998a; Marcus, 1998b; Marcus, 2001).
В работе видно, что проблемы обобщения за пределы пространства тренировочных примеров остаются и у текущих ГО-сетей, почти 20 лет спустя. Многие рассмотренные в статье проблемы — жадность до данных, уязвимость к обману, проблемы с нечёткими выводами и переносом — можно считать расширением фундаментальной проблемы. Современные нейросети хорошо работают с задачами, не отходящими далеко от основных тренировочных данных, но начинают барахлить в случаях, отдаляющихся на периферию.
Популярное добавление свёртки гарантирует решение одного определённого класса проблем, похожих на мою проблему идентичности: т.н. трансляционная инвариантность, при которой объект сохраняет идентичность даже при изменении расположения. Но это решение не общее, как показывают недавние демонстрации Лэйка. Ещё один способ решения проблем с ГО — это расширение набора данных, но такие попытки лучше работают в двумерном зрении, чем с языком.
И всё же для ГО пока не существует общего решения проблемы обобщения за пределами тренировочного пространства. И именно по этой причине нам необходимо искать разные решения, если мы хотим добиться создания ИИОН.
4. Потенциальные риски чрезмерной шумихи
Один из величайших рисков текущей шумихи, связанной с ИИ — ещё одна «зима ИИ», как та, что разрушила эту область в 1970-х, после отчёта Лайтхилла (Lighthill, 1973), где предполагалось, что ИИ слишком хрупкий, узконаправленный и искусственный, чтобы его можно было использовать на практике. И хотя сейчас практических приложений для ИИ гораздо больше, чем в 1970-х, шумиха остаётся поводом для волнения. Когда такая влиятельная фигура, как Эндрю Ын, даёт в Harvard Business Review обещания неминуемой автоматизации, не соответствующие реальности, существует риск провала ожиданий. Машины не могут, на самом деле, делать много того, что обычные люди способны сделать за секунду, начиная от надёжного осознания мира, и заканчивая пониманием предложений. Никакой здоровый человек не перепутает черепаху с ружьём, а знак парковки с холодильником.
Швыряющиеся инвестициями в ИИ директора могут оказаться разочарованными, особенно учитывая плохое состояние области понимания естественного языка. Уже сейчас многие крупные проекты, отменяются, например, M project от Facebook, запущенный в августе 2015 года, и широко рекламировавшийся, как персональный помощник общего назначения, а потом низведённый до куда как меньшей роли помощника в небольшом наборе хорошо определённых задач вроде добавления записи в календарь.
Можно достаточно уверенно сказать, что чатботы не оправдали той шумихи, что получили пару лет назад. Если, к примеру, робомобили тоже разочаруют общественность, и, по контрасту с шумихой, окажутся ненадёжными после масштабного выхода на рынок, или просто не окажутся полностью автономными после стольких обещаний, вся область ИИ может резко остановиться и потерять популярность и финансирование. Мы уже можем видеть намёки на такое развитие, как в статье в журнале Wired под названием «После пика шумихи робомобили попали в провал разочарования».
Есть и другие серьёзные опасения, и не только апокалиптического толка (последний, кстати, пока что остаётся в области научной фантастики). Лично я более всего опасаюсь, что область ИИ может застрять в локальном минимуме, слишком отклонившись в неправильную часть интеллектуального пространства, слишком сконцентрировавшись на детальном изучении определённого класса доступных, но ограниченных моделей, основанных на решении легкодоступных задач — игнорируя более рискованные отклонения от маршрута, которые в итоге могут привести нас на более надёжный путь.
Я вспоминаю об известном (пусть и уже устаревшем) порицании Питером Тилем часто слишком узко мыслящей техноиндустрии: "Мы хотели увидеть летающие автомобили, а получили ограничение в 140 символов". Я всё ещё мечтаю о Рози-Роботе [робот-домохозяйка из мультсериала Джетсоны середины XX века / прим. перев.] — домашнем роботе, способном на любую работу, который бы ухаживал за моим домом. Но пока, через шесть десятилетий развития ИИ, наши боты не делают почти ничего более серьёзного, чем играют музыку, подметают полы и кликают на рекламу.
Жаль, если прогресс не пойдёт дальше. У ИИ есть риски, но и великолепные потенциальные преимущества. Величайшим вкладом ИИ в общества, по моему мнению, должна стать автоматизация научных открытий, что, в числе прочего, приведёт к появлению гораздо более сложных вариантов медицинского обслуживания, чем существующие сегодня. Но для этого нам надо убедиться, что эта область исследований не застрянет в локальном минимуме.
5. Что можно улучшить?
Несмотря на все обрисованные мною проблемы, я не думаю, что ГО нужно забрасывать. Мы должны поменять его концепцию: это не универсальный растворитель, но просто один из множества инструментов, мощный шуруповёрт в мире, где нужны молотки, гаечные ключи и пассатижи, не говоря уже о стамесках, свёрлах, вольтметрах, логических зондах и осциллоскопах. В классификации восприятия, где есть огромное количество данных, ГО будет мощным инструментом; в других, более богатых областях когнитивистики он не будет работать так хорошо. Вопрос в том, где ещё нам искать? Вот некоторые из возможностей.
5.1 Спонтанное обучение
В интервью оба пионера ГО Джеоф Хинтон и Янн Лекун недавно указали на спонтанное обучение как на один из способов пройти дальше контролируемого обучения ГО, требовательного к количеству данных.
Уточню, что ГО и СО не противопоставляются друг другу. ГО обычно используется в контролируемом контексте с размеченными данными, но есть способы использования ГО и спонтанным образом. Но несомненно во многих областях существуют причины для того, чтобы отойти от запроса на массивное количество данных, обычно требуемых для контролируемого ГО.
Терминами СО, или неконтролируемым обучением, обычно обозначают несколько типов систем. Один распространённый тип «накапливает» вместе входные данные, обладающие
схожими свойствами, даже если они явно и не размечены. Модель распознавания кошек от Google (Le et al., 2012), возможно, будет наиболее известным примером такого подхода.
Ещё один подход, рекламируемый исследователями (Luc, Neverova, Couprie,
Verbeek, & LeCun, 2017), не исключающий первый — замена наборов размеченных данных такими вещами, как фильмы, меняющимися во времени. Идея в том, что системы, тренированные на видеороликах, могут использовать любую пару последовательных кадров в качестве эрзац-сигнала в обучении, цель которого — предсказать следующий кадр; кадр t становится прогнозом для кадра t1, без всякой необходимости для человека ставить метки.
Мне кажется, что оба эти подхода полезны, но сами по себе не решают проблем, описанных в разделе 3. Система всё ещё остаётся жадной до данных, ей не хватает явных меток, и такой подход не предлагает того, что могло бы подвинуть нас в сторону неопределённых выводов, интерпретируемости или лёгкости в нахождении ошибок.
Существует, однако, другой подход к неконтролируемому обучению, который мне кажется очень интересным: подход, практикуемый человеческими детьми. Дети часто ставят сами себе новую задачу — построить башню из кубиков Lego, пролезть через небольшое пространство, как моя дочка недавно пробовала пролезть сквозь стул — между сиденьем и спинкой. При решении такого рода задач на изучение пространства часто используется самостоятельная постановка задач (что мне делать?) и решение проблем высокого уровня (как мне просунуть руку через стул, если всё остальное уже пролезло?), а также интеграцию абстрактных знаний (как работают тела, какие размеры и допуски есть у разных предметов, и так далее). Если мы сможем создать системы, способные на постановку собственных целей, рассуждение и решение проблем на более абстрактном уровне, за этим может последовать очень быстрый и качественный прогресс.
5.2 Манипуляция символами и необходимость в гибридных моделях
Ещё одним направлением поисков должно стать исследование классического, "символического ИИ", который иногда называют GOFAI [Good Old-Fashioned AI — «добрый, старый ИИ»]. Символический ИИ основан на идее, центральной для математики, логики и информатики — представлении абстракций при помощи символов. Уравнения вроде F = ma позволяют нам вычислять выходные данные на основе широкого спектра входных данных, вне зависимости от того, видели ли мы какие-нибудь определённые величины раньше; строки компьютерных программ делают то же самое (если величина x больше величины y, выполнить действие a).
Сами по себе символические системы часто оказываются хрупкими, но их в основном разрабатывали в эпоху, когда данных и вычислительных мощностей было гораздо меньше, чем сегодня. Сегодня правильным шагом будет интегрировать ГО, отлично справляющееся с перцепционной классификации, с символическими системами, отлично работающими с выводами и абстракциями. Это объединение можно считать аналогией мозгу; системы перцепционного ввода, как и соматосенсорная кора, занимается чем-то похожим на ГО, но есть и другие части мозга, например, префронтальная кора и центр Брока, работающие, судя по всему, на высшем уровне абстракции. Мощность и гибкость мозга происходит, в частности, из его способности динамически интегрировать прямую сенсорную информацию со сложными абстракциями, касающимися объектов и их свойств, источников света, и так далее.
Уже существует несколько соблазнительных шагов в направлении интеграции, включая нейросимволическое моделирование (Besold et al., 2017) и недавнюю тенденцию к созданию таких систем, как дифферецируемые нейрокомпьютеры (Graves et al., 2016), программирование с дифференцируемыми интерпретаторами (Bošnjak, Rocktäschel, Naradowsky, & Riedel, 2016), и нейропрограммирование с дискретными операциями (Neelakantan, Le, Abadi, McCallum, & Amodei, 2016). И хотя эти работы ещё не дошли до полномасштабного ИИОН, я давно утверждал (Marcus, 2001), что интеграция операций, похожих на то, что происходит в микропроцессорах, в нейросети, может быть чрезвычайно полезным.
С той точки зрения, что мозг можно рассматривать, как «широкий спектр вычислительных примитивов, пригодных к повторному использованию — элементарных модулей обработки, похожих на набор базовых инструкций в микропроцессоре — возможно, соединённых вместе параллельно, как в настраиваемой интегральной микросхеме, известной, как программируемая пользователем вентильная матрица», как я писал в другой работе (Marcus, Marblestone, & Dean, 2014), шаги в направлении обогащения набора инструкций, из которых состоят наши вычислительные системы, должны пойти нам на пользу.
5.3 Больше идей из когнитивной психологии и психологии развития
Ещё одно потенциально плодотворное место для поисков — человеческие когнитивные способности (Davis & Marcus, 2015; Lake et al., 2016; Marcus, 2001; Pinker & Prince, 1988). Машинам не обязательно буквально воспроизводить человеческий разум, который, вообще говоря, подвержен ошибкам и не идеален. Но остаётся множество областей, от понимания естественного языка до здравого смысла, в которых люди обладают преимуществом. Изучение механизмов, лежащих в основе этих сильных сторон человека может привести к прорывам в области ИИ, даже если целью не будет, и не должно, являться точное воспроизведение человеческого разума.
Для многих обучение на примере людей означает нейробиологию; с моей точки зрения, это преждевременный вывод. Нам ещё недостаточно много известно в области нейробиологии для того, чтобы провести реинжиниринг мозга, и возможно, не будет известно ещё несколько десятилетий подряд — вероятно, до тех пор, пока ИИ не улучшится. ИИ может помочь нам расшифровать работу мозга, а не наоборот.
В любом случае в это время должно быть возможно использовать технологии и идеи, почёрпнутые из когнитивистики и психологии развития, для создания более надёжного и всеобъемлющего ИИ и моделей, поддерживаемых не только математикой, но и определёнными свойствами человеческой психологии.
Хорошей отправной точкой может служить понимание внутренних механизмов работы человеческого разума, и использование их в качестве гипотез для создания механизмов, которые могут оказаться полезными для разработки ИИ. В другой статье, которую я ещё подготавливаю, я привожу подборку возможностей, некоторые из которых были получены из моих ранних исследований (Marcus, 2001), а другие — из работ Элизабет Спелке (Spelke & Kinzler, 2007). Возможности, взятые из моих работ, фокусируются на репрезентации и манипуляции информацией, например, символьными механизмами, представляющими переменные и различия между типами и представителями класса; у Спелке позаимствована концентрация на том, как младенцы могут представлять себе такие понятия, как пространство, время и объект.
Второй точкой фокусировки может быть понимание здравого смысла, как его выработки (часть его может быть врождённой, довольно большая порция — выученной), как он представляется, как он встраивается в процесс нашего взаимодействия с реальным миром (Davis & Marcus, 2015). Недавние работы Лерера (Lerer et al, 2016), Уоттерса с коллегами (Watters and colleagues, 2017), Тененбаума с коллегами (Wu, Lu, Kohli, Freeman, & Tenenbaum, 2017) и моя с Дэвисом (Davis, Marcus, & Frazier-Logue, 2017) предлагают некоторые соперничающие подходы к тому, как это осмыслить, работая в области повседневных физических рассуждений.
Третьей точкой может быть понимание человеком рассказов — эту идею давно уже предлагали (Roger Schank and Abelson,1977), и её пора освежить (Marcus, 2014; Kočiský et al., 2017).
5.4 Более сложные задачи
Останется ли ГО в текущем виде, превратится ли во что-то новое, или вообще исчезнет — в любом случае необходимо рассмотреть набор проблем, подталкивающих системы к развитию за пределы того, чему можно научиться в рамках парадигмы контролируемого обучения на больших наборах данных. Вот несколько соображений, некоторые из которых взяты из статьи в AI Magazine, посвящённой движение за пределы теста Тьюринга, которую я редактировал совместно с коллегами (Marcus, Rossi, Veloso — AI Magazine, & 2016, 2016):
- Задача на осмысление (Paritosh & Marcus, 2016; Kočiský et al., 2017), которая потребует от системы просмотра произвольного видео (чтения текста, прослушивания подкаста) и ответов на нечёткие вопросы о том, что в нём содержалось. (Кто главный герой? Какова его мотивация? Что будет, если его соперник добьётся своего?) Ни один специально подготовленный набор тренировочных данных не сможет покрыть все возможные случае; тут потребуется умение делать выводы и знания о реальном мире.
- Научное рассуждение и понимание, такое, какое даётся в задачах института Allen AI для восьмого класса (Schoenick, Clark, Tafjord, P, & Etzioni, 2017; Davis, 2016). И хотя ответы на некоторые базовые вопросы по науке можно просто найти в интернете, другие потребуют выводов, находящихся за пределами того, что было непосредственно объявлено и связи со знаниями общего характера.
- Участие в играх разного рода (Genesereth, Love, & Pell, 2005) с переносом знаний между играми (Kansky et al., 2017), так, чтобы, например, знания, полученные при обучении игры в стрелялку от первого лица, могли улучшать показатели в другой похожей игре совершенно другого внешнего вида, с другим оборудованием и так далее. Тут не подойдёт система, способная обучаться игре во множество игр раздельно, без переноса между ними, как это делает Atari game system от DeepMind — суть в том, чтобы собирать накапливающееся знание, которое можно переносить.
- Физическая проверка робота, управляемого ИИ, на постройку каких-либо вещей (Ortiz Jr, 2016), от палаток до укрытий из IKEA, на основе инструкций и взаимодействия с объектами реального мира, вместо обширного количества попыток научиться методом проб и ошибок.
Какой-то одной задачи будет недостаточно. Естественный интеллект многомерен (Gardner, 2011), и, учитывая сложность мира, ИИОН тоже должен быть многомерным.
Выходя за рамки перцепционной классификации, и переходя в более широкую интеграцию выводов и знаний, ИИ сможет очень сильно продвинуться вперёд.
6. Заключение
Чтобы понять прогресс, происходящий в этой области, можно рассмотреть достаточно пессимистичную статью, написанную мною для The New Yorker 5 лет назад, где был сделан следующий вывод: «ГО — только часть более крупной задачи создания интеллектуальных машин», поскольку «таким технологиям недостаёт способов представления причинно-следственных связей (таких, как связь между болезнями и их симптомами), а также им будет очень трудно справляться с такими абстрактными понятиями, как „близкие родственники“ или „идентичность“. У них нет очевидных способов построения логических выводов, и им ещё далеко до интеграции абстрактных знаний, таких, как что собой представляют объекты, для чего они нужны, как они обычно используются».
Как мы увидели, многие из этих опасений остаются актуальными, несмотря на общее продвижение в отдельных областях вроде распознавания речи, машинного перевода и настольных игр, и на впечатляющий прогресс в области доступной вычислительной инфраструктуры и объёма данных.
Что интересно, в прошлом году всё больше учёных начали упирать на сходные ограничения. Частичный список включает в себя Brenden Lake and Marco Baroni (2017), François Chollet (2017), Robin Jia and Percy Liang (2017), Dileep George and others at Vicarious (Kansky et al., 2017) and Pieter Abbeel and colleagues at Berkeley (Stoica et al., 2017).
Возможно, самым заметным поступком будет смена собственного мнения Джоффом Хинтоном, который в интервью на сайте Axios признался, что у него есть «глубокие сомнения» в эффективности метода обратного распространения ошибки, ключевой особенности ГО, которую он сам помогал разрабатывать, поскольку его волнует зависимость этого метода от набора размеченных данных. Вместо этого он предположил, что «возможно, придётся изобрести совершенно новые методы».
Я разделяю с Хинтоном радостное предвкушение будущего прогресса в этой области.
Список упомянутых работ
- Athalye, A., Engstrom, L., Ilyas, A., & Kwok, K. (2017). Synthesizing Robust Adversarial Examples. arXiv, cs.CV.
- Besold, T. R., Garcez, A. D., Bader, S., Bowman, H., Domingos, P., Hitzler, P. et al. (2017). Neural-Symbolic Learning and Reasoning: A Survey and Interpretation. arXiv, cs.AI.
- Bošnjak, M., Rocktäschel, T., Naradowsky, J., & Riedel, S. (2016). Programming with a Differentiable Forth Interpreter. arXiv.
- Bottou, L. (2015). Two big challenges in machine learning. Proceedings from 32nd International Conference on Machine Learning.
- Bowman, S. R., Angeli, G., Potts, C., & Manning, C. D. (2015). A large annotated corpus for learning natural language inference. arXiv, cs.CL.
- Chollet, F. (2017). Deep Learning with Python. Manning Publications.
- Cireşan, D., Meier, U., Masci, J., & Schmidhuber, J. (2012). Multi-column deep neural network for traffic sign classification. Neural networks.
- Davis, E., & Marcus, G. (2015). Commonsense reasoning and commonsense knowledge in artificial intelligence. Communications of the ACM, 58(9)(9), 92-103.
- Davis, E. (2016). How to Write Science Questions that Are Easy for People and Hard for Computers. AI magazine, 37(1)(1), 13-22.
- Davis, E., Marcus, G., & Frazier-Logue, N. (2017). Commonsense reasoning about containers using radically incomplete information. Artificial Intelligence, 248, 46-84.
- Deng, J., Dong, W., Socher, R., Li, L. J., Li — Computer Vision and, K., & 2009 Imagenet: A large-scale hierarchical image database. Proceedings from Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on.
- Elman, J. L. (1990). Finding structure in time. Cognitive science, 14(2)(2), 179-211.
- Evtimov, I., Eykholt, K., Fernandes, E., Kohno, T., Li, B., Prakash, A. et al. (2017). Robust Physical-World Attacks on Deep Learning Models. arXiv, cs.CR.
- Fodor, J. A., & Pylyshyn, Z. W. (1988). Connectionism and cognitive architecture: a critical analysis. Cognition, 28(1-2)(1-2), 3-71.
- Gardner, H. (2011). Frames of mind: The theory of multiple intelligences. Basic books.
- Gelman, S. A., Leslie, S. J., Was, A. M., & Koch, C. M. (2015). Children’s interpretations of general quantifiers, specific quantifiers, and generics. Lang Cogn Neurosci, 30(4)(4), 448-461.
- Genesereth, M., Love, N., & Pell, B. (2005). General game playing: Overview of the AAAI competition. AI magazine, 26(2)(2), 62.
- George, D., Lehrach, W., Kansky, K., Lázaro-Gredilla, M., Laan, C., Marthi, B. et al. (2017). A generative vision model that trains with high data efficiency and breaks text-based CAPTCHAs. Science, 358(6368)(6368).
- Gervain, J., Berent, I., & Werker, J. F. (2012). Binding at birth: the newborn brain detects identity relations and sequential position in speech. J Cogn Neurosci, 24(3)(3), 564-574.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT press.
- Graves, A., Wayne, G., Reynolds, M., Harley, T., Danihelka, I., Grabska-Barwińska, A. et al. (2016). Hybrid computing using a neural network with dynamic external memory. Nature, 538(7626)(7626), 471-476.
- Henderson, P., Islam, R., Bachman, P., Pineau, J., Precup, D., & Meger, D. (2017). Deep Reinforcement Learning that Matters. arXiv, cs.LG.
- Huang, S., Papernot, N., Goodfellow, I., Duan, Y., & Abbeel, P. (2017). Adversarial Attacks on Neural Network Policies. arXiv, cs.LG.
- Jia, R., & Liang, P. (2017). Adversarial Examples for Evaluating Reading Comprehension Systems. arXiv.
- Kahneman, D. (2013). Thinking, fast and slow (1st pbk. ed. ed.). New York: Farrar, Straus and Giroux.
- Kansky, K., Silver, T., Mély, D. A., Eldawy, M., Lázaro-Gredilla, M., Lou, X. et al. (2017). Schema Networks: Zero-shot Transfer with a Generative Causal Model of Intuitive Physics. arXIv, cs.AI.
- Kočiský, T., Schwarz, J., Blunsom, P., Dyer, C., Hermann, K. M., Melis, G. et al. (2017). The NarrativeQA Reading Comprehension Challenge. arXiv, cs.CL.
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In (pp. 1097-1105).
- Lake, B. M., Salakhutdinov, R., & Tenenbaum, J. B. (2015). Human-level concept learning through probabilistic program induction. Science, 350(6266)(6266), 1332-1338.
- Lake, B. M., Ullman, T. D., Tenenbaum, J. B., & Gershman, S. J. (2016). Building Machines That Learn and Think Like People. Behav Brain Sci, 1-101.
- Lake, B. M., & Baroni, M. (2017). Still not systematic after all these years: On the compositional skills of sequence-to-sequence recurrent networks. arXiv.
- Lazer, D., Kennedy, R., King, G., & Vespignani, A. (2014). Big data. The parable of Google Flu: traps in big data analysis. Science, 343(6176)(6176), 1203-1205.
- Le, Q. V., Ranzato, M.-A., Monga, R., Devin, M., Chen, K., Corrado, G. et al. (2012). Building high-level features using large scale unsupervised learning. Proceedings from International Conference on Machine Learning.
- LeCun, Y. (1989). Generalization and network design strategies. Technical Report CRG-TR-89-4.
- Lerer, A., Gross, S., & Fergus, R. (2016). Learning Physical Intuition of Block Towers by Example. arXiv, cs.AI.
- Lighthill, J. (1973). Artificial Intelligence: A General Survey. Artificial Intelligence: a paper symposium.
- Lipton, Z. C. (2016). The Mythos of Model Interpretability. arXiv, cs.LG.
- Lopez-Paz, D., Nishihara, R., Chintala, S., Schölkopf, B., & Bottou, L. (2017). Discovering causal signals in images. Proceedings from Proceedings of Computer Vision and Pattern Recognition (CVPR).
- Luc, P., Neverova, N., Couprie, C., Verbeek, J., & LeCun, Y. (2017). Predicting Deeper into the Future of Semantic Segmentation. International Conference on Computer Vision (ICCV 2017).
- Marcus, G., Rossi, F., Veloso — AI Magazine, M., & 2016. (2016). Beyond the Turing Test. AI Magazine, Whole issue.
- Marcus, G., Marblestone, A., & Dean, T. (2014). The atoms of neural computation. Science, 346(6209)(6209), 551-552.
- Marcus, G. (in prep). Innateness, AlphaZero, and Artificial Intelligence.
- Marcus, G. (2014). What Comes After the Turing Test? The New Yorker.
- Marcus, G. (2012). Is “Deep Learning” a Revolution in Artificial Intelligence? The New Yorker.
- Marcus, G. F. (2008). Kluge: the haphazard construction of the human mind. Boston: Houghton Mifflin.
- Marcus, G. F. G. F. (2001). The Algebraic Mind: Integrating Connectionism and cognitive science. Cambridge, Mass.: MIT Press.
- Marcus, G. F. (1998a). Rethinking eliminative connectionism. Cogn Psychol, 37(3)(3), 243-282.
- Marcus, G. F. (1998b). Can connectionism save constructivism? Cognition, 66(2)(2), 153-182.
- Marcus, G. F., Pinker, S., Ullman, M., Hollander, M., Rosen, T. J., & Xu, F. (1992). Overregularization in language acquisition. Monogr Soc Res Child Dev, 57(4)(4), 1-182.
- Marcus, G. F., Vijayan, S., Bandi Rao, S., & Vishton, P. M. (1999). Rule learning by sevenmonth- old infants. Science, 283(5398)(5398), 77-80.
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. arXiv.
- Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G. et al. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540)(7540), 529-533.
- Neelakantan, A., Le, Q. V., Abadi, M., McCallum, A., & Amodei, D. (2016). Learning a Natural Language Interface with Neural Programmer. arXiv.
- Ng, A. (2016). What Artificial Intelligence Can and Can’t Do Right Now. Harvard Business Review.
- Nguyen, A., Clune, J., Bengio, Y., Dosovitskiy, A., & Yosinski, J. (2016). Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space. arXiv, cs.CV.
- Nguyen, A., Yosinski, J., & Clune, J. (2014). Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images. arXiv, cs.CV.
- Norvig, P. (2016). State-of-the-Art AI: Building Tomorrow’s Intelligent Systems. Proceedings from EmTech Digital, San Francisco.
- O’Neil, C. (2016). Weapons of math destruction: how big data increases inequality and threatens democracy.
- Ortiz Jr, C. L. (2016). Why we need a physically embodied Turing test and what it might look like. AI magazine, 37(1)(1), 55-63.
- Paritosh, P., & Marcus, G. (2016). Toward a comprehension challenge, using crowdsourcing as a tool. AI Magazine, 37(1)(1), 23-31.
- Pearl, J. (2000). Causality: models, reasoning, and inference /. Cambridge, U.K.; New York Cambridge University Press.
- Pinker, S., & Prince, A. (1988). On language and connectionism: analysis of a parallel distributed processing model of language acquisition. Cognition, 28(1-2)(1-2), 73-193.
- Ribeiro, M. T., Singh, S., & Guestrin, C. (2016). “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. arXiv, cs.LG.
- Sabour, S., Frosst, N., & Hinton, G. E. (2017). Dynamic Routing Between Capsules. arXiv, cs.CV.
- Samek, W., Wiegand, T., & Müller, K.-R. (2017). Explainable Artificial Intelligence: Understanding, Visualizing and Interpreting Deep Learning Models. arXiv, cs.AI.
- Schank, R. C., & Abelson, R. P. (1977). Scripts, Plans, Goals and Understanding: an Inquiry into Human Knowledge Structures. Hillsdale, NJ: L. Erlbaum.
- Schmidhuber, J. (2015). Deep learning in neural networks: An overview. Neural networks.
- Schoenick, C., Clark, P., Tafjord, O., P, T., & Etzioni, O. (2017). Moving beyond the Turing Test with the Allen AI Science Challenge. Communications of the ACM, 60 (9)(9), 60-64.
- Sculley, D., Phillips, T., Ebner, D., Chaudhary, V., & Young, M. (2014). Machine learning: The high-interest credit card of technical debt. Proceedings from SE4ML: Software Engineering for Machine Learning (NIPS 2014 Workshop).
- Socher, R., Huval, B., Manning, C. D., & Ng, A. Y. (2012). Semantic compositionality through recursive matrix-vector spaces. Proceedings from Proceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning.
- Spelke, E. S., & Kinzler, K. D. (2007). Core knowledge. Dev Sci, 10(1)(1), 89-96.
- Stoica, I., Song, D., Popa, R. A., Patterson, D., Mahoney, M. W., Katz, R. et al. (2017). A Berkeley View of Systems Challenges for AI. arXiv, cs.AI.
- Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I. et al. (2013). Intriguing properties of neural networks. arXiv, cs.CV.
- Vinyals, O., Toshev, A., Bengio, S., & Erhan, D. (2014). Show and Tell: A Neural Image Caption Generator. arXiv, cs.CV.
- Watters, N., Tacchetti, A., Weber, T., Pascanu, R., Battaglia, P., & Zoran, D. (2017). Visual Interaction Networks. arXiv.
- Williams, A., Nangia, N., & Bowman, S. R. (2017). A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference. arXiv, cs.CL.
- Wu, J., Lu, E., Kohli, P., Freeman, B., & Tenenbaum, J. (2017). Learning to See Physics via Visual De-animation. Proceedings from Advances in Neural Information Processing Systems.
- Zoph, B., Vasudevan, V., Shlens, J., & Le, Q. V. (2017). Learning Transferable Architectures for Scalable Image Recognition. arXiv, cs.CV.