
/ Flickr / Faris Algosaibi / CC
Однако эта машина, которая выглядела как кукла турка, на самом деле оказалась искусной иллюзией. Рукой «турка» управлял человек, сидящий в столе. Все это был лишь дешевый фокус — секрет работы аппарата раскрыли только в 1850 году. С тех пор и до того момента, когда человечеству удалось создать машину, победившую чемпиона мира по шахматам, прошло больше двух столетий. В 1996 году компьютер Deep Blue от IBM выиграл матч у Гарри Каспарова.
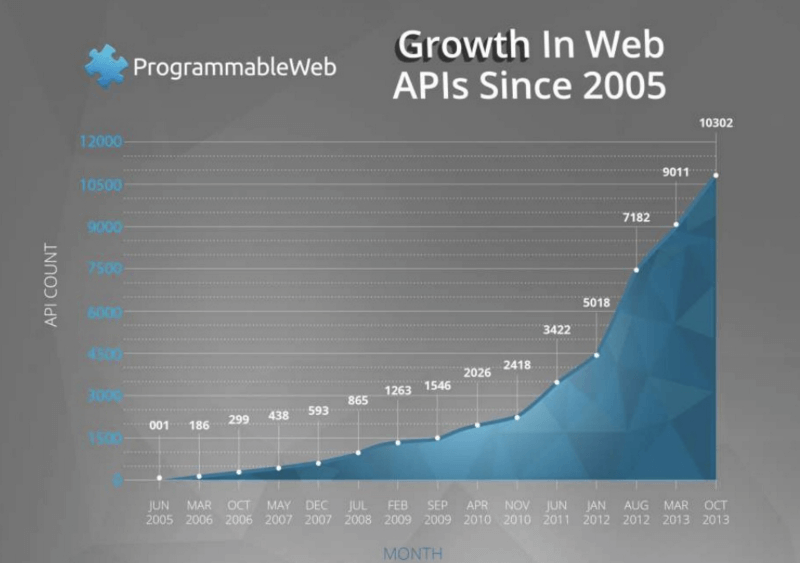
Источник: ProgrammableWeb
Через четыре года с того момента — в 2000 году — Рой Филдинг (Roy Fielding) опубликовал свою работу на тему «Архитектурные стили и проектирование сетевых архитектур программного обеспечения», которая позднее ляжет в основу архитектурного стиля REST API.
В том же году компания Salesforce выпустила первую версию своего API для автоматизации продаж. За ней последовала платформа eBay, а затем и другие интернет-компании. Участники рынка вскоре поняли, какие преимущества способны предоставить интерфейсы программирования приложений. Количество API начало расти.
Новые «автоматические» машины
Когда один из сервисов делает доступным свой интерфейс для общественности, после этого человек пишет для него документацию и делится ей. Потом уже другой человек находит эту документацию и, используя полученный опыт, пишет программу, которая может обращаться с этим интерфейсом. Получается, что люди выступают в качестве посредников для коммуникации M2M. Все это очень сильно напоминает фокус с турком-шахматистом.
На сегодняшний день при работе с API инженеры сталкиваются с трудностями в следующих аспектах:
- Синхронность
- Контроль версий
- Масштабирование
- Поиск
Синхронность
Сегодня документация к API пишется и распространяется еще до того, как две машины «встречаются» друг с другом. Даже если проигнорировать тот факт, что люди могут неправильно понять написанное, существует проблема, связанная с изменением документации. Согласовывать API-документацию достаточно сложно, а поддерживать и обновлять клиент — еще сложнее.
Контроль версий
REST играет большую роль в успехе веб-API и отлично согласуется с основами функционирования Сети. Поскольку большинство API не следуют принципам REST, API-клиенты часто оказываются привязанными к используемым интерфейсам. Это создает крайне хрупкую систему.
Более того, чтобы обновить существующий клиент в случае изменения API необходимо затратить время и средства, да и сам процесс достаточно медленный. По этой причине API не эволюционируют. Вместо этого, на их основе строятся новые API, «загрязняя» кодовую базу.
Масштабирование
Сегодня все больше компаний создают API для каждой задачи, которая может заинтересовать пользователя. Многие компании начинают с единого API, но затем всегда приходят к более индивидуальным решениям.
Чтобы создать новые API, приходится нанимать все больше программистов. Это ведет к увеличению сложности поддержки системы. Однако не важно, сколько людей мы нанимаем, когда дело касается написания и чтения документации или адаптации существующих проектов к изменениям в API — эта часть работы плохо масштабируется. Плюс всегда есть место для недопонимания и иной трактовки формулировок — язык способен давать слишком большое пространство для маневров.
Поиск
И, наконец, следует отметить проблему с поиском API. Как нам узнать, что есть сервис, который мы бы хотели использовать? Возможно уже есть проект, который бы позволил сэкономить время при создании собственного решения. Не важно, что на рынке есть другой геолокационный сервис, узнать о его существовании достаточно сложно. Приходится уповать на «сарафанное радио» и поисковые системы.
Возможное решение
«Чтобы создать полностью автономные API, необходимо разработать и распространить словари предметной области, которые система поиска будет ассоциировать с API», — говорит Зденек Немек (Zdenek Nemec), основатель консалтинговой компании Good API.
Работа автономной системы может выглядеть следующим образом:
- Машина публикует свой интерфейс вместе с профайлом, описывающим его, и словарем предметной области. Затем она регистрирует себя в службе поиска API.
- Затем другая машина опрашивает сервис поиска, используя термины из словарей. Если API, использующие их, найдены, то сервис поиска сообщает о существовании нужного сервиса.
- Теперь клиент может использовать API для своих нужд (считается, что он уже был «натренирован» для работы с запрашиваемым словарем).
Например, больше не придется разрабатывать погодное приложение для определённого сервиса. Вместо этого, вы создаете клиент, который знает, как отображать прогноз погоды, и будет «общаться» с сервисами AccuWeather, Weather Underground и другими погодными приложениями, которые используют такие же словари.
«И строительные блоки для создания подобной системы уже начинают появляться, — отмечает Зденек. — Например, контроллеры HATEOAS распространяются с помощью одного из форматов гипермедиа, а адаптация формата JSON-LD уже набирает популярность в API-индустрии, а поисковые провайдеры Google, Microsoft, Yahoo и Yandex поддерживают словарь Schema.org. Наконец, начинают появляться API-каталоги, например HitchHQ и Rapid API».
Возможно, в будущем API позволят исключить человеческий фактор в вопросах составления документации и поиска, а мы начнем программировать API-клиенты декларативно, используя словари и другую открытую информацию. Это позволит с новой силой начать разработки подключенных устройств, беспилотных автомобилей и прогрессивных медицинских технологий.
Другие материалы из блогов провайдера виртуальной инфраструктуры «ИТ-ГРАД»: